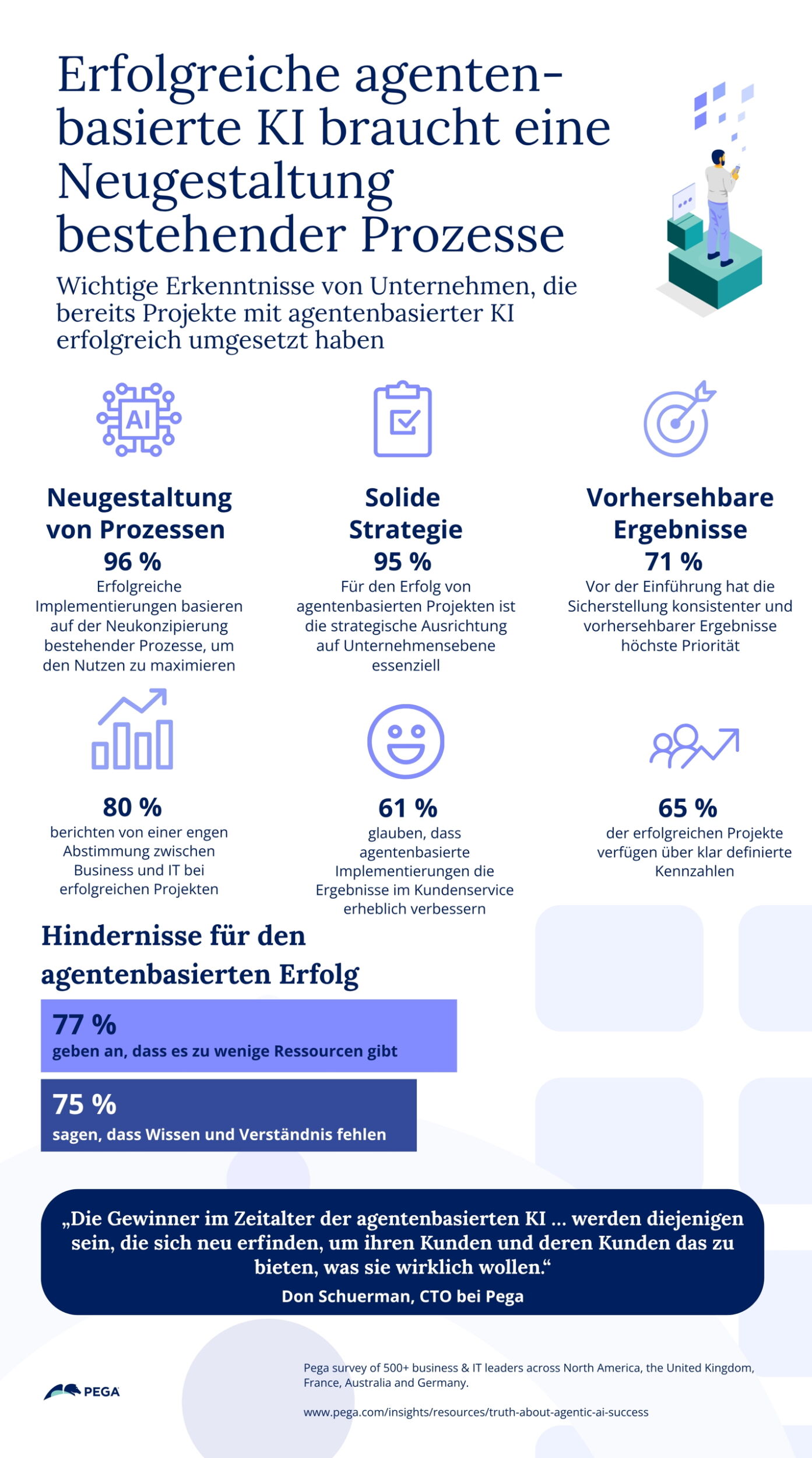
Anders als klassische Steuerungen wie speicherprogrammierte Steuerung (SPS), die auf klaren deterministischen Logiken basieren, operiert Physical AI in offenen Problemräumen. Durch diese Anwendungen werden künstliche Intelligenz und die physische Welt verbunden, sei es durch das Erfassen realer Daten über Sensorik oder durch aktives Eingreifen via Robotik und Anlagensteuerung. Dadurch wirken sich Fehler und Manipulationen nicht nur auf den digitalen Raum aus, sondern verursachen auch Schäden in der realen Welt. Der Dienstleistungsanbieter zeigt auf, welche Risiken besonders kritisch sind und wie Unternehmen ihnen effektiv begegnen können.
1. Vulnerable Sensorik
Für die meisten Physical-AI-Anwendungen bilden Sensoren die Grundlage, um notwendige Daten zu liefern. Werden diese Sensoren durch gezielte Manipulation oder äußere Einflüsse gestört, kann das System falsche Entscheidungen treffen.
Um Risiken zu minimieren, können Unternehmen auf den Ansatz der Sensorfusion zurückgreifen, bei dem Daten mehrerer Sensoren miteinander abgeglichen werden. Auch der Einsatz von Tests, die inkonsistente oder auffällige Messwerte automatisch erkennen, ist sinnvoll. Ergänzend kann die Redundanz kritischer Sensoren, eine regelmäßige Kalibrierung und die Überwachung von Anomalien in Echtzeit die Robustheit der Physical-AI-Systeme deutlich erhöhen.
2. Angriffe auf KI-Modelle
Durch manipulierte Trainingsdaten oder fehlerhafte Modellaktualisierungen können auch die zugrunde liegenden KI-Modelle Fehler Fehlentscheidungen treffen. Solche Manipulationen oder Fehler sind oft schwer zu erkennen, weil die Ergebnisse weiterhin plausibel erscheinen.
Um dies zu vermeiden, können kontrollierte Trainingspipelines, sorgfältige Validierung der Trainingsdaten und kontinuierliches Monitoring der Modellentscheidungen dabei helfen, Anomalien frühzeitig zu erkennen. Ergänzend können Versionierung der Modelle und Audits der Trainingsprozesse die Integrität der KI-Modelle sichern.
3. Neue Angriffsflächen durch Vernetzung
Die starke Vernetzung von Physical-AI-Systemen bietet zwar hohe Flexibilität, aber dadurch auch eine große Angriffsfläche. Kompromittierte Zugänge oder unsichere Schnittstellen können genutzt werden, um Systeme gezielt zu manipulieren oder Kontrolle über physische Prozesse zu erlangen.
Indem klassische Security-Mechanismen, z.B. Zero-Trust-Architekturen, konsequente Netzwerksegmentierung und abgesicherte Update-Prozesse zentral bleiben, werden die Risiken reduziert. Ergänzend sind kontinuierliches Monitoring der Kommunikationswege sowie ein umfassendes Logging von Zugriffen notwendig, um unautorisierte Aktivitäten frühzeitig zu erkennen und einzugrenzen.
4. Trennung von Safety und Security
In der industriellen Automatisierung wurden Safety (Schutz vor Fehlern und Unfällen) und Security (Schutz vor Angriffen) lange getrennt betrachtet. Durch die Nutzung von Physical AI, bei der Systeme in offenen, schwer vollständig modellierbaren Umgebungen agieren und häufig direkt mit Menschen zusammenarbeiten, können Fehlerhafte oder manipulierte Entscheidungen unmittelbare physische Auswirkungen haben. Ein System kann formal ’sicher‘ ausgelegt sein und dennoch durch unerwartetes oder durch beeinflusstes Verhalten gefährlich werden.
5. Unerwartete Situationen in realen Umgebungen
Physical-AI-Systeme müssen mit unvorhersehbaren Situationen umgehen: ungewöhnliche Objekte, beschädigte Sensoren oder veränderte Umweltbedingungen, die sich jedoch nur teilweise im Training abbilden lassen. Dadurch kann die Systemstabilität gefährden.
Durch umfangreiche Simulationen und Stresstests, in denen Systeme bewusst mit außergewöhnlichen Situationen konfrontiert werden, können diese Risiken umgangen werden. nomalieerkennung, adaptive Algorithmen und kontinuierliches Lernen unterstützen ebenfalls dabei, dass Physical-AI-Anwendungen auch in unvorhergesehenen Umgebungen zuverlässig reagieren. Zusätzlich ermöglichen Data Flywheels, also ein selbstverstärkender Kreislauf aus Daten, Produktverbesserung und Nutzung, ein kontinuierliches Lernen.