Die Entwicklung eines Systems für die optische Qualitätssicherung nimmt immer Zeit in Anspruch. Die Einrichtung der Hardware muss zwar produktspezifische Eigenschaften und individuelle Rahmenbedingungen vor Ort berücksichtigen, ist in der Regel aber gut und vergleichsweise schnell realisierbar. Im Gegensatz dazu erfordern Konfiguration und Programmierung der Software für die zuverlässige Fehlerfindung deutlich mehr Zeit. Hier eröffnet Deep Learning die Möglichkeit, Entwicklungszeiten stark zu reduzieren. Den Schlüssel dafür stellen Selbstlernmechanismen dar. Sie ersetzen die Programmierung der klassischen Bildverarbeitung. Die Computer Vision basiert auf Regeln, die für jedes Prüfobjekt neu entwickelt werden. Die Erkennungsmuster für die Unterscheidung gut/schlecht werden dabei einzeln programmiert. Diese Methode hat aber zwei Nachteile: Sie funktioniert nur wirklich gut, wenn sich gut/schlecht deutlich unterscheiden und die Entwicklung dauert lange, d.h. sie kann durchaus sechs Monate oder länger in Anspruch nehmen. Ein Einflussfaktor für die Entwicklungszeit ist die leichte oder schwere Erkennbarkeit der Fehler. Ein anderer ist die geforderte Erkennungssicherheit. Wenn 98 Prozent Sicherheit genügen, ist die Entwicklung eher abgeschlossen, als wenn das Nichterkennen von Fehlern (False Negative) unbedingt verhindert werden soll.
Entwicklungszeiten können teuer werden
Neue Perspektiven bietet die optische Qualitätssicherung mit Deep Learning, da die Algorithmen in der Regel zu deutlich reduzierten Entwicklungszeiten führen. Das wird möglich, indem das Kodieren jedes einzelnen Fehlers durch das Einlernen mit Fehlerbildern ersetzt wird. Hierbei wird die Fähigkeit von neuronalen Netzen genutzt, sich an die Prüfobjekte zu adaptieren und damit selbsttätig zu lernen. Das Trainieren der Gut/Schlecht-Unterscheidung beginnt bei Deep Learning immer mit Bildern der Prüfobjekte. Oft sind diese bereits vorhanden, da zuvor Bildverarbeitung im Prozess durchgeführt wurde. Ansonsten müssen zuerst Bilder von fehlerhaften und fehlerfreien Teilen produziert werden. Künstliche Intelligenz (KI) verspricht die Revolution der Fertigung, doch in der Praxis scheitern viele Projekte an einer unzureichenden Datenbasis. Warum Sie erst Ordnung schaffen müssen, bevor Sie Künstliche Intelligenz erfolgreich nutzen können. ‣ weiterlesen
Ohne Datenordnung keine Effizienz: Wie Sie Ihre Produktion KI-ready machen
In der Regel benötigt Deep Learning eine vierstellige Anzahl von Bildern. Bei den meisten Deep-Learning-Anwendungen werden bei Bildern von fehlerhaften Teilen die Mängel im Bild markiert. Durch diese sogenannte Annotation lernt das Deep-Learning-Modell, wo das Prüfobjekt fehlerhaft ist. Die Anzahl der Bilder lässt sich einfach steigern, indem annotierte Bilder gedreht oder gespiegelt werden (Augmentation). Dadurch entstehen für die Software neue Prüfaufgaben, auch wenn das zugrundeliegende Motiv gleich ist. Ein ebenfalls wichtiger Teil der Vorbereitung ist die Bestimmung der Hyperparameter, d.h. Basiswerte zur Steuerung des Lernalgorithmus. Mit denen stellen KI-Experten das Lernmodell auf die jeweilige Prüfaufgabe ein. Diese Phase dauert oft etwa vier Wochen, abhängig unter anderem von der Verfügbarkeit von Bildmaterial. Sind Lernmodell und Hyperparameter bestimmt, beginnt die Erprobung der Software im realen Prozess. Die Entwickler testen das neue Lernmodell in der Produktion auf Gut/Schlecht-Erkennung. Danach wird das Ergebnis ausgewertet, das Modell verbessert und ein neuer Test durchgeführt. Dieser Zyklus wird so lange wiederholt, bis die Erkennungsrate für die Qualitätsverantwortlichen zufriedenstellend ist. Die grundlegende Entwicklung eines solchen Lernmodells dauert etwa vier Wochen. Daran schließt sich die meist mehrwöchige Testphase an.
Stark verkürzte Entwicklungszeit
Schneller geht die Entwicklung mit der Deep-Learning-Software AI.See der Münchner Firma Elunic. Der Anbieter setzt gleich an mehreren Punkten an, um mit der Software die Entwicklungszeit zu reduzieren. AI.See ist auf Fehlererkennung spezialisiert. Deswegen sind die mitgelieferten Modelle leichter auf typische Aufgaben der Qualitätssicherung zu trainieren als generische Modelle. Zusätzlich bietet sich die Möglichkeit zur Verwendung von Modellen, die bereits an ähnlichen Aufgaben eingelernt wurden (pre-trained). Schließlich sehen Kratzer oder Lunker auf ähnlichen Oberflächen meist auch ähnlich aus. Dadurch ermöglicht die Software bereits hohe Erkennungsraten mit weniger Fehlerbildern als vergleichbare Lösungen und beginnt daher das Einlernen schon mit einem zeitlichen Vorsprung. Einen weiteren Zeitvorteil gewinnt die Software durch das automatische Setzen der bestmöglichen Hyperparameter, denn diese werden nicht von Experten ausgewählt und erprobt. Die Software rechnet Kombinationen von Hyperparametern durch, die sich zuvor bei ähnlichen Projekten bewährt haben. Das beste Ergebnis bestimmt sie anhand der zuvor eingelesenen Bilder. Die Augmentation führt die Software ebenfalls automatisch durch. Diese umfangreiche Automatisierung ist möglich durch die Verwendung einer leistungsfähiger, auf Deep Learning ausgelegter Hardware. Im Ergebnis schrumpft damit die Dauer der Konfiguration des Lernmodells von Wochen auf Tage. AI.See kommt so mit vergleichsweise wenig Bildern aus, da es sich mit seinen spezialisierten Modellen schnell auf typische Erkennungsaufgaben einstellen kann. In einfachen Fällen genügen schon ein paar Hundert.
Praktische Anwendung nach einer Woche
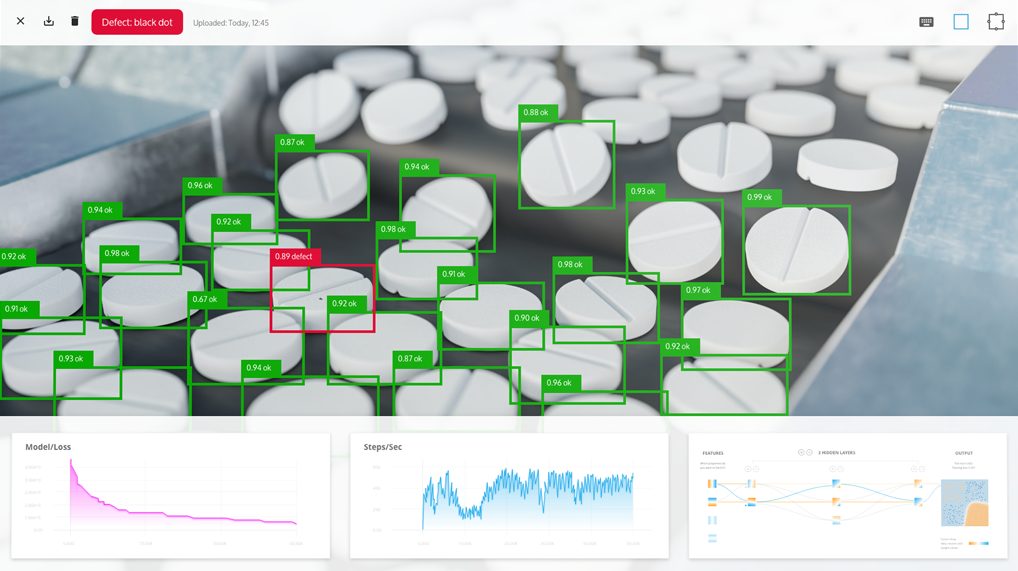
In der Praxis kann oft schon nach einer Woche das Einlernen der Software im Prozess beginnen. Das Einlernen in der Anlage wird nicht in Etappen durchgeführt, wie oft bei anderen Deep-Learning-Systemen, sondern kontinuierlich. Die Software prüft ein Produkt nach dem anderen und legt dabei dem Operator Zweifelsfälle vor. Dieser stuft das Produkt als gut oder schlecht ein. Dadurch generiert er ein weiteres Bild, das den Bestand klassifizierter Bilder für das Deep Learning ergänzt. Die Anlaufphase wird somit bestmöglich zum Lernen genutzt. Auf diese Weise erreicht die Software oft schon nach wenigen Wochen eine zufriedenstellende Erkennungsleistung. Abhängig von der benötigten Erkennungsrate und der Menge an produzierten Defektteilen kann das Training so lange aufrechterhalten werden, bis eine ausreichende Erkennungsleistung erreicht ist. Für sicherheitskritische Anwendungszwecke, etwa in den Bereichen Pharma und Medizintechnik, ist eine weitere Eigenschaft von AI.See von Vorteil. Nutzer der Software müssen die Lernphase nie beenden, sie werden im Laufe der Nutzung aber immer seltener befragt. Dadurch wird das Lernmodell immer besser, wodurch der Personalaufwand kontinuierlich sinkt und bei seltenen Fehlern dennoch der Faktor Mensch die finale Entscheidung übernimmt.