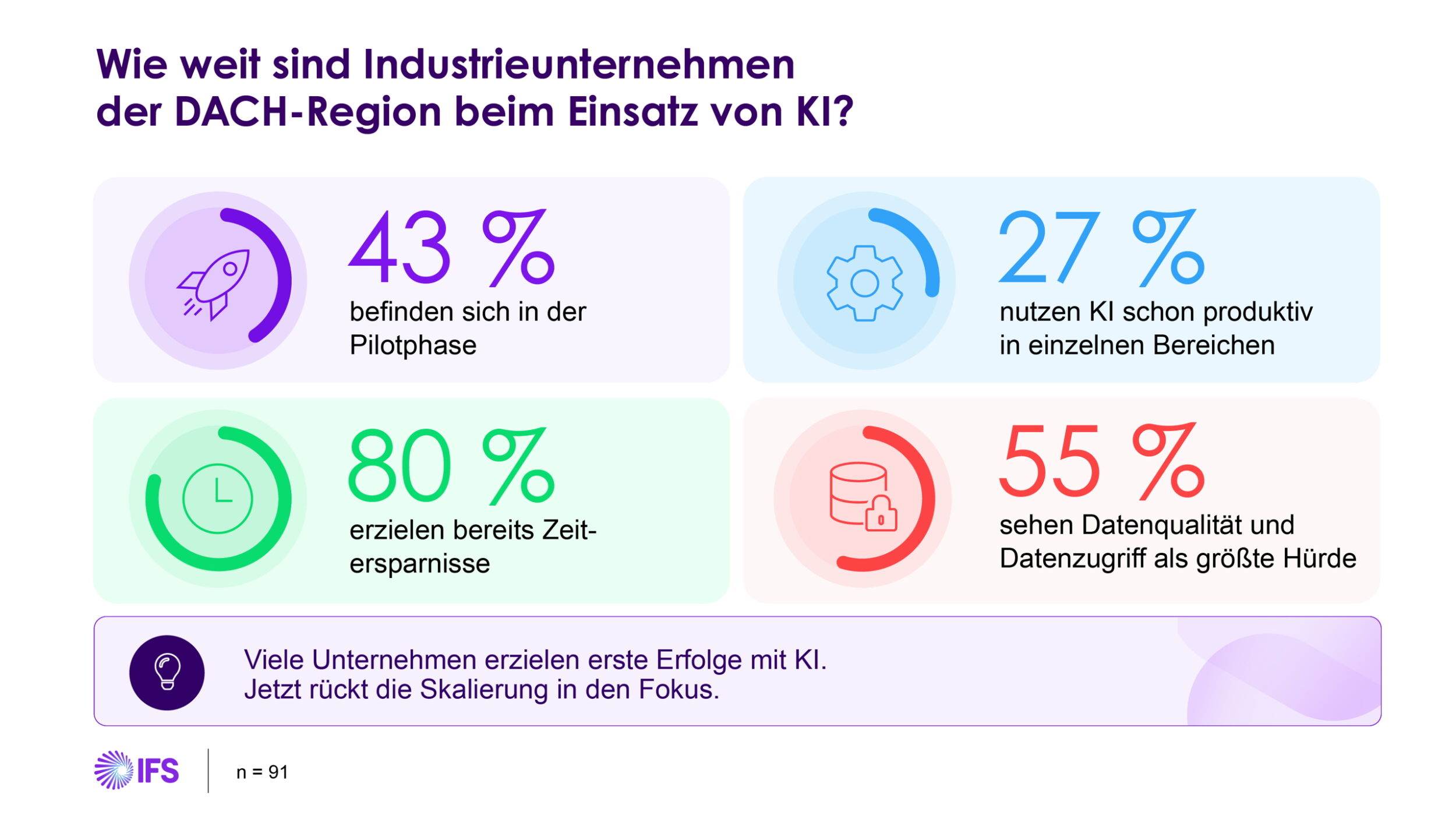
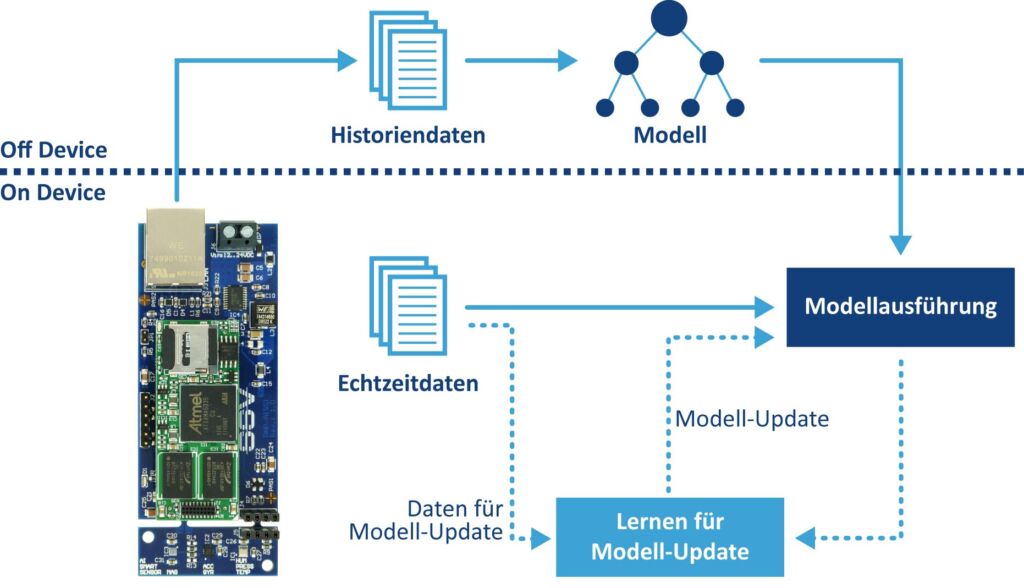
Bisher wird der gewünschte Zusammenhang zwischen den jeweiligen Eingangs- und Ausgangsdaten einer Automatisierungsbaugruppe mittels wissensbasierter Regeln in einer Hoch- oder SPS-Programmiersprache kodiert und auf einem eingebetteten System ausgeführt. In Zukunft lassen sich Embedded-Systeme in der Automatisierung auch per Supervised Machine Learning für eine bestimmte Aufgaben trainieren.
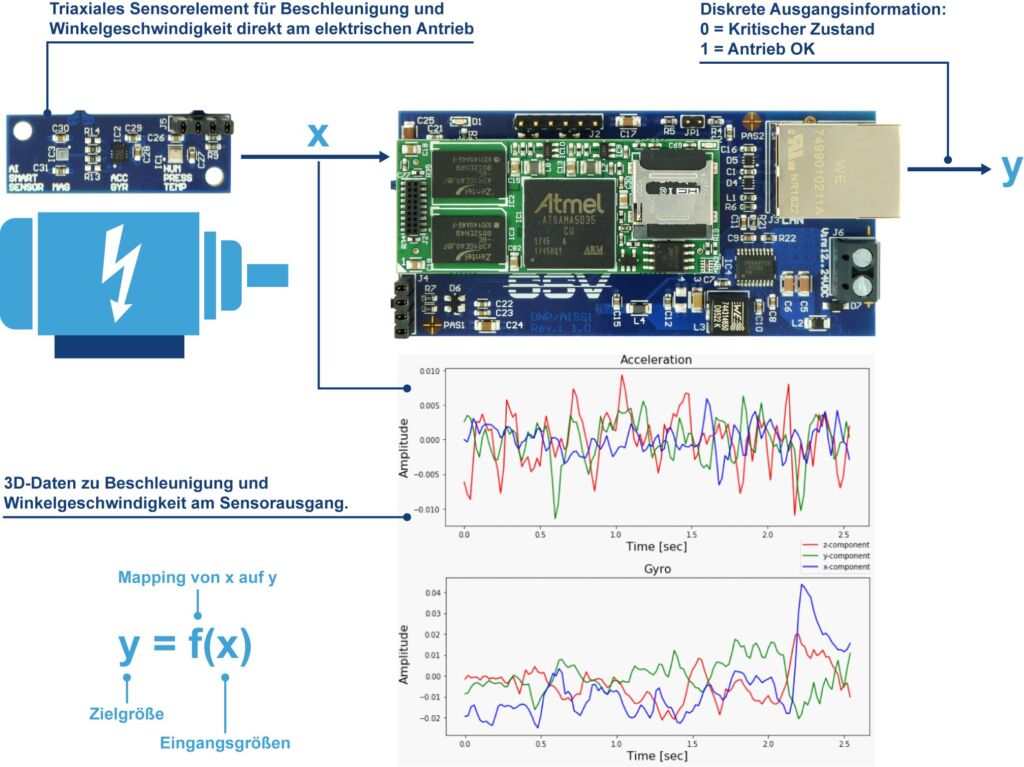
In unzähligen eingebetteten Systemen diverser Automatisierungskomponenten wird eine in speziellen Hochsprachen erstellte Firmware genutzt, die den jeweils gewünschten Zusammenhang zwischen Ein- und Ausgangssignalen anhand von statischen Regeln herstellt, die auf lexikalisches Wissen basieren. Ein typischer Anwendungsfall aus dem Predictive-Maintenance-Umfeld wäre beispielsweise eine komplexe Sensorikapplikation zur Zustandsüberwachung eines elektrischen Antriebs mit Hilfe von triaxialen Beschleunigungs- und Winkelgeschwindigkeitssensoren: Die Mikrorechner-Firmware im Sensorsystem verarbeitet die analogen Rohdaten der einzelnen Sensorelemente und liefert anhand eines programmierten Regel-basierten Messverfahrens (welche Frequenzen und Amplituden sind jeweils zulässig?) das gewünschte digitale Ausgangssignal. Klassische Firmware-Entwicklungen für komplexe eingebettete Systeme sind aufwändig und über die gesamte Produktlebensdauer betrachtet, relativ unflexibel. Jede noch so kleine Änderung der Anforderungen löst einen neuen Entwicklungszyklus aus. Durch die zahlreichen Weiterentwicklungen im Bereich der künstlichen Intelligenz (KI) ist nun ein weiterer Lösungsansatz möglich: Zwischen die Ein- und Ausgangsdaten eines Mikrorechners wird ein lernfähiger Machine-Learning-Algorithmus geschaltet und mittels spezieller Trainingsdaten für eine bestimmte Aufgabenstellung konfiguriert. Dabei entsteht ein mathematisches Modell, das den jeweiligen Zusammenhang der Ein- und Ausgänge abbildet. Anforderungsänderungen werden durch eine erneute Trainingsphase und mit Hilfe zusätzlicher Referenzdaten umgesetzt. Grundsätzlich lässt sich mit dieser Vorgehensweise jedes Problem lösen, dessen Zusammenhang zwischen Ein- und Ausgängen durch ein mathematisches Modell beschreibbar ist.
Varianten des maschinellen Lernens
Da die wesentlichen Grundlagen der künstlichen Intelligenz und des maschinellen Lernens aus den 50er Jahren stammen, gibt es mittlerweile eine schwer überschaubare Algorithmenvielfalt. Insgesamt lässt sich das maschinelle Lernen in drei Bereiche gliedern:
Supervised Learning: Überwachtes maschinelles Lernen. Die meisten der gegenwärtig in der Praxis genutzten Machine-Learning-Algorithmen, wie zum Beispiel CNNs (Convolutional Neural Networks) gehören zu dieser Kategorie. Bei diesem Verfahren ist der Zusammenhang zwischen den Eingangs- und Ausgangsgrößen anhand von Historiendaten im Vorfeld bekannt. Insofern haben wir es mit einem Mapping der Eingangsdaten auf den Ausgang zu tun, wie es auch bei unzähligen klassischen Automatisierungs-Programmieraufgaben der Fall ist. Der jeweils zum Einsatz kommende Algorithmus muss zunächst trainiert werden. Dabei entsteht ein Modell. Für die Trainingsphase werden gelabelte (Historien-) Daten benötigt. Bei einer sinnvollen Abstimmung zwischen den Daten und dem jeweils gewählten Algorithmus sowie einer ausreichenden Trainingsdatenmenge von guter Qualität lassen sich anschließend mit Hilfe bisher unbekannter Datenwerte relativ genaue diskrete Klassifizierungs- oder kontinuierliche Regressionswerte vorhersagen. Typische Anwendungsbeispiele für überwachtes Lernen sind die Objekterkennung in Bilddaten (Mustererkennung) und die Vorhersage des Energiebedarfs einer Maschine. Die in der Trainingsphase des Supervised Machine Learnings entstehenden Modelle sind statisch und müssen bei Bedarf durch ein erneutes Training an veränderte Bedingungen angepasst werden.
Unsupervised Learning: Unüberwachtes maschinelles Lernen. Dieses Verfahren wird bei Bedarf auf Daten mit unbekannten Zusammenhängen angewendet, um in den Eingangsdaten mit Rechnerunterstützung nach Mustern (Clustern) und den Grenzen zwischen den gefundenen Clustern zu suchen. Insofern spricht man bei dieser Kategorie des maschinellen Lernens auch häufig von Clusteranalysen, also die Zuordnung der vorliegenden Datenpunkte zu bestimmten Gruppen (den Clustern). Die in der Mathematik zur Verfügung stehenden Methoden nutzen unterschiedliche Ansätze, wie das prototypische Bilden von Cluster-Zentren in einem n-dimensionalen kontinuierlichen Raum (K-means-Methodik) oder Dichte-basierte Regionen als Zentrum eines möglichen Clusters (DBSCAN-Algorithmus). Darüber hinaus gibt es auch noch hierarchische Clusterverfahren. Die gefundenen Ähnlichkeitsstrukturen und die per Clusteranalyse festgelegten Gruppen können in der Praxis als Vorlage zum Labeln der bisher unbekannten Daten für ein anschließendes Supervised Machine Learning dienen.
Reinforcement Learning: Bestärkendes maschinelles Lernen. Beim Reinforcement Learning (RL) steht die Interaktion eines lernenden Agenten mit seiner Umwelt im Mittelpunkt. Mit Hilfe des RL können Computer nicht nur Brettspiele wie Schach oder Go gewinnen. Diese Methodik des maschinellen Lernens spielt inzwischen auch für Embedded Systeme in der Robotik und bei autonom agierenden Logistiksystemen, etwa vollautonome Flurförderzeuge wie Gabelstapler eine sehr wichtige Rolle. Des Weiteren nutzen Staubsaug- oder Rasenmähroboter im Haus oder Garten beispielsweise den zum RL gehörenden Q-Learning-Algorithmus, um unter anderem ohne fremde Hilfe den Weg zur Ladestation zu finden. Die Zusammenhänge beim RL sind relativ einfach: Die Umwelt des Agenten, die von diesem beeinflusst werden kann, besitzt eine bestimmte Anzahl von Zuständen. Jede Aktion des Agenten führt zu einem anderen Umweltzustand, für den der Agent als ‚Reinforcement‘ eine Belohnung erhält – z.B. einen Wert zwischen 0 und 100. Anhand der Belohnungsintensität kann der Algorithmus selbstständig eine Strategie mit der besten Abfolge von Schritten erlernen, die zum jeweiligen Ziel führt.
Embedded Machine Learning
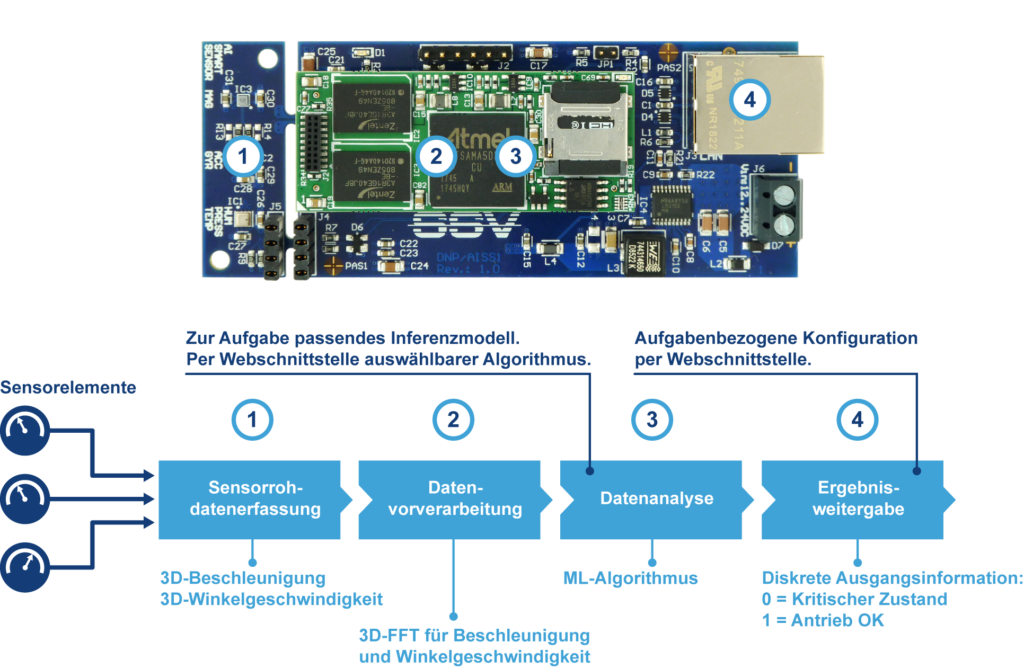
Beim Einsatz eines Supervised Machine Learning auf eingebetteten Systemen in der Automatisierung lässt sich für bestimmte Zielapplikationen inzwischen ein deutlich größerer Nutzen als durch die bisher üblichen Softwareentwicklungsprozesse erzielen. Für Aufgabenstellungen, bei denen der Zusammenhang zwischen den Ein- und Ausgangsdaten vorher bekannt oder aus größeren Datenmengen automatisch erlernbar ist, muss nicht unbedingt eine anwendungsbezogene Firmware entwickelt werden. Es kann stattdessen auch ein Standard-Algorithmus für überwachtes Lernen auf einem eingebetteten Mikrorechner implementiert werden, der dann mit gelabelten Beispieldaten im Hinblick auf die Aufgabenstellung trainiert oder mit einem extern trainierten Modell versorgt wird. Vergleicht man die einzelnen Schritte einer programmierten Condition-Monitoring-Lösung für einen elektrischen Antrieb mit dem Machine-Learning-Ansatz, ergibt sich folgendes Gesamtbild: @WK Einrückung:Sensorrohdatenerfassung: Hier gibt es praktisch keinen Unterschied zwischen beiden Lösungsansätzen. Sensordatenerfassung, Digitalisierung und die Auswahl der Zahlendarstellung (Integer- oder Floating Point-Format) ist in jedem Fall zu codieren. @WK Einrückung:Datenvorverarbeitung: Für Schwingungsdaten, wie in der Abbildung 1 dargestellt, ist in der Regel eine FFT (Fast Fourier Transform) vor der eigentlichen Datenanalyse sinnvoll. Auch dieser Algorithmus zur diskreten Fourier-Transformation ist in beiden Fällen per Firmware zu implementieren. @WK Einrückung:Automatische Datenanalyse: Hier gibt es wesentliche Unterschiede. Die Programmierung einer Datenanalyse setzt voraus, dass dem Entwicklerteam das Wissen um die Frequenzen und Amplituden, die einen bestimmten Antriebszustand kennzeichnen, mit allen Details zur Verfügung steht. Beim Machine-Learning-Ansatz ist das nicht erforderlich. Genaugenommen spielt noch nicht einmal die Antriebscharakteristik selbst eine Rolle. @WK Einrückung:Ergebnisweitergabe: Mit welcher physikalischen und logischen Schnittstelle, z.B. Ethernet und Profinet, das Ergebnis der Datenanalyse weitergegeben wird, ist ebenfalls Lösungsansatz-agnostisch.
Zusammenfassend lässt sich feststellen, dass insbesondere die automatische Datenanalyse einer Sensorikapplikation zur Zustandsüberwachung mit Hilfe des maschinellen Lernens sehr viel einfacher und flexibler realisiert werden kann.