Moderne Anwendungen gehen heute immer besser auf die Bedürfnisse der Nutzer ein. Jedoch kommt die Zuverlässigkeit der Infrastruktur durch häufig eingespielte Updates auch zuweilen an Grenzen. Dies zeigt sich dem Benutzer durch Leistungsprobleme oder im schlimmsten Fall durch den Ausfall des digitalen Services.
Für die Reaktion auf Schwierigkeiten mit der Performanz der Infrastruktur brauchen IT-Teams Tools, um Leistungsprobleme überbrücken zu können. Viele der eher cloudnativen Ansätze sind für Site Reliability Engineers (SREs) allerdings zu undurchsichtig. Gefragt sind mehr Einblicke, die als Grundlage dienen, um Prioritäten richtig setzen sowie ein Problem schnell identifizieren und beheben zu können.
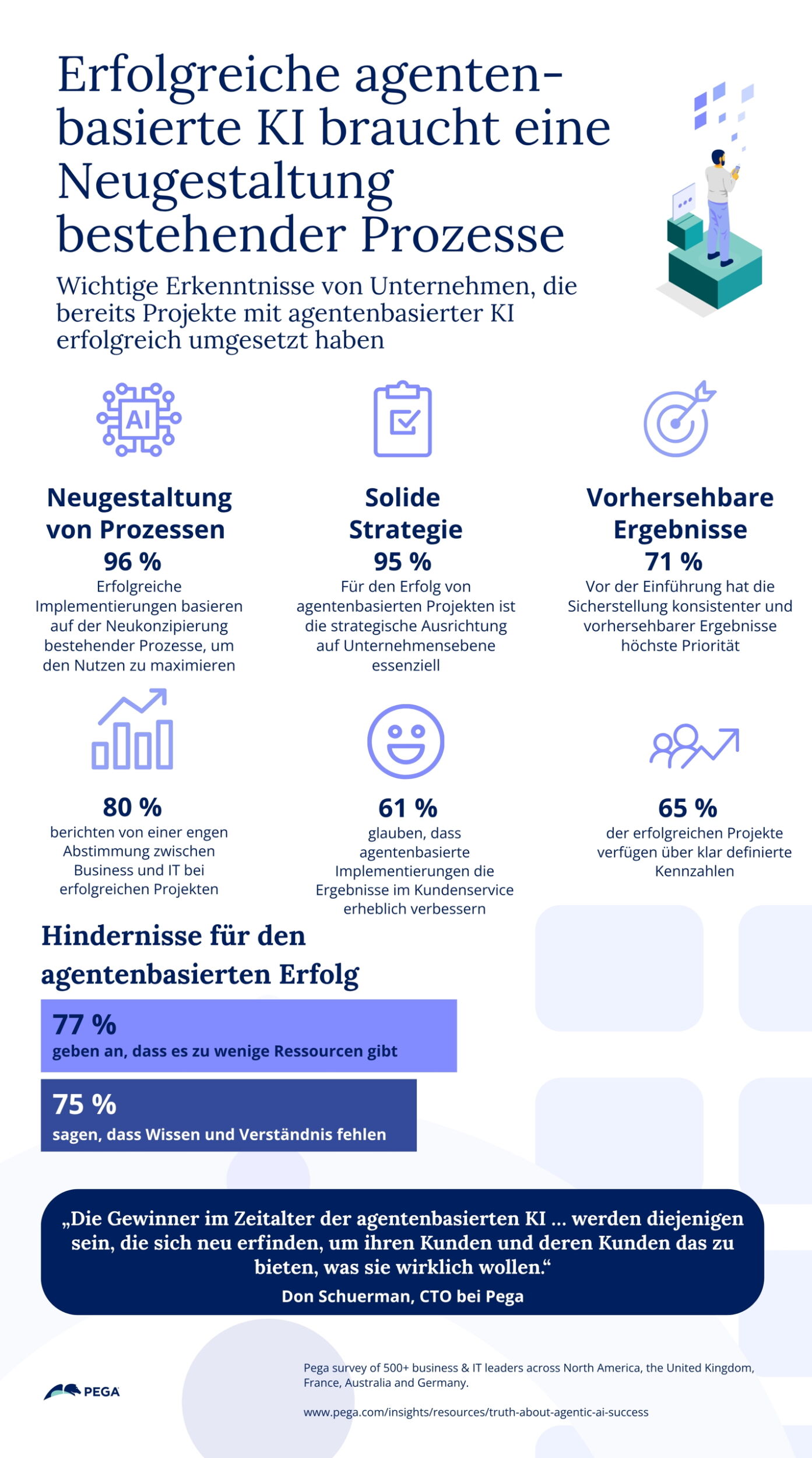
KI-Werkzeug zum Fehler aufspüren

AIOps kann mithilfe von KI und maschinellen Lernen den IT-Spezialisten aufzeigen, wo es Anomalien gibt und deren Ursache identifizieren. So können Probleme aufgedeckt und behoben werden – und sie zu schwerwiegenden Beeinträchtigungen führen. Das wird auch deswegen wichtiger, weil der zu verwaltende Software- und Infrastrukturbestand stetig wächst.
AIOps spielt seine Stärke dort aus, wo große schnell wachsende Mengen an Leistungsdaten – egal ob Observability- und Engagement-Daten oder Daten von anderen Tools – im Spiel sind. Um die Teams bei der Identifizierung und Diagnose eines Problems zu unterstützen, werden Algorithmen und Tools für maschinelles Lernen auf die Daten angewandt. So sollen Prozesse nachvollziehbarer und die Verwaltung von Zwischenfällen automatisierbarer werden. Es gibt mindestens fünf Möglichkeiten, wie AIOps in der Praxis eingesetzt werden kann:
1. Zwischenfälle erkennen
KI und maschinelles Lernen beginnen, Anomalien zu verstehen und wenden dieses Wissen darauf an, Systeme und Infrastrukturen zu monitoren. Dieser Ansatz ermöglicht es, frühe Warnzeichen herauszufiltern und zu prozessieren. Teams werden schneller auf ein Problem aufmerksam, noch bevor ein Anwender etwas merkt.
2. Reduzieren des Alert-Rauschens
Die Flut von Alarmmeldungen ist eine Herausforderung für IT-Teams. Sie führt zu Abstumpfungseffekten, was bei kritischen Alerts fatal sein kann. Es kann sinnvoll sein, Alarmbenachrichtigungen mit niedriger Priorität zu unterdrücken, und solche, die miteinander in Verbindung stehen, zu gruppieren. AIOps korreliert, unterdrückt und priorisiert Vorfälle, damit sich Teams auf die Probleme konzentrieren können, die die Zuverlässigkeit des Systems am meisten gefährden.
3. Der richtige Kontext als Basis
Zwischenfälle versetzen Teams schnell in einen stressigen Krisenmodus. AIOps ist so angelegt, dass in derartigen Fällen das Geschehen automatisch abgebildet wird und so ein ganzheitliches Bild für einen Vorfall liefert. So kann eine Störung nicht nur verstanden, sondern als Reaktion darauf schnell behoben werden.
4. Aus der Vergangenheit lernen
AIOps-Tools lernen stetig dazu, es sind schließlich Machine Learning-Anwendungen. Erfahrungen aus der Vergangenheit, die aktuelle Nutzung und das Feedback von Anwendern liefern Daten, damit ähnliche Probleme kein zweites Mal auftreten. AIOps ist grundsätzlich darauf ausgerichtet, Korrelationen zu erkennen und passende Empfehlungen zur Problembehebung und -vermeidung zu liefern.
5. Integrierte Daten helfen dem Team
Daten zu Zwischenfällen aus angebundenen Quellen können in das Ereignismanagement integriert werden. Eine AIOps-Lösung nimmt diese Daten auf, reichert sie mit Kontext an und sendet Benachrichtigungen an Teams oder Responder in den eingesetzten Incident Management Tools. New Relics Observability-Plattform bietet beispielsweise eine Zweiwege-Integration mit PagerDuty und anderen gängigen Lösungen für das Incident Management an. Je mehr Daten eingehen, desto bessere Handlungsempfehlungen kann AIOps liefern.
Nicht als Block Box gedacht
Die Unterstützung durch KI und maschinelles Lernen stellt bei AIOps nur eine Handlungsempfehlung dar. Es soll für Transparenz im Stack sorgen und Optimierungspotenzial aufzeigen – bei möglichem manuellem Feedback. Die Implementierung von AIOps samt Anomalie-Detection soll mit überschaubarem Aufwand möglich sein, denn basierend auf SRE-Kernsignalen lassen sich Anomalien über Anwendungen, Services und Log-Daten zügig ausmachen.