Die AIM Agile IT Management hat sich darauf spezialisiert, Data Lakes zur Sammlung von historischen und Rohdaten anzulegen und in Betrieb zu nehmen, wie sie zur Entwicklung von industriellen KI-Anwendungen benötigt werden. Ein Data Lake hat die Aufgabe, Daten aus einer Datenquelle unstrukturiert und ohne eine Transformation zu speichern. So wird jede Änderung an Datensätzen roh abgelegt. Im späteren Verlauf entsteht eine Datenbasis, die sich zur Lösung von Problemstellungen analysiert lässt. Das illustriert folgendes Beispiel. Für die Softwarefirma MediFox sollte mit industrieller KI eine Anwendung erstellt werden, die die Kündigungswahrscheinlichkeit ihrer Kunden vorhersagen kann. Mit Hilfe einer solchen Vorhersage (Churn Prediction) sollte auf ein eventuelles Kündigungsrisiko reagiert werden können. Die Churn Prediction sollte aufgrund der vorhandenen Daten des Kundeninformationssystems (KIS), des Customer-Relationship-Management-Systems (CRM) und des Servicedesks des Kunden realisiert werden. Im Fall einer Churn-Prediction-Anwendung kann man durch eine nachträgliche Transformation auf die notwendigen Daten zugreifen:
- Wann hat sich ein Ansprechpartner beim Endkunden geändert?
- Wann hat der Endkunde neue Lizenzen erworben bzw. wann wurde eine Lizenz verändert oder abbestellt?
- Wie ist die Zahlungsmoral des Kunden über die Zeit hinweg?
- Hierzu werden die Rohdaten aus drei verschiedenen Systemen benötigt:
- Endkundeninformationen aus dem Kundeninformationssystem (KIS)
- Rohdaten zu Service Requests und Incidents aus dem Jira Servicedesk
- Lizenzinformationen aus einer Lizenzdatenbank.
Asynchrone Datenverarbeitung
Zunächst werden die Rohdaten aus den Systemen extrahiert. Dazu muss für jedes System eine geeignete Schnittstelle identifiziert werden. Generell können Daten aus Systemen per Push- oder Pull-Mechanismus extrahiert werden und werden dann mithilfe eines Service in einen Kafka Topic geschrieben. Nun können die Daten asynchron verarbeitet werden, somit wird auch das eventuelle Risiko eines Rückstaus bei der Extraktion minimiert. Gleichzeitig stellt Kafka sicher, dass ein transaktionaler Kontext die Konsistenz aller zu speichernden Daten sicherstellt. Die zu speichernden Daten können ebenso binäre Formate enthalten, da die Transformation in weiterführende Daten bei der Ablage noch keine Rolle spielt. „Da wir in einer privaten Cloud beginnen und später in eine AWS- oder Microsoft-Azure- basierte Umgebung zur Speicherung der Daten im Data Lake wechseln können müssen, nutzen wir MinIO als Abstraktion des Dateisystems. MinIO stellt aus Sicht der Applikation immer einen S3-Bucket zur Verfügung. Auf diese Weise sind auch hybride Umgebungen oder Umzüge der Datenbasis kein Problem für den Data Lake“, sagt Carsten Hilber, AIM Co-Founder & DevOps Engineer.
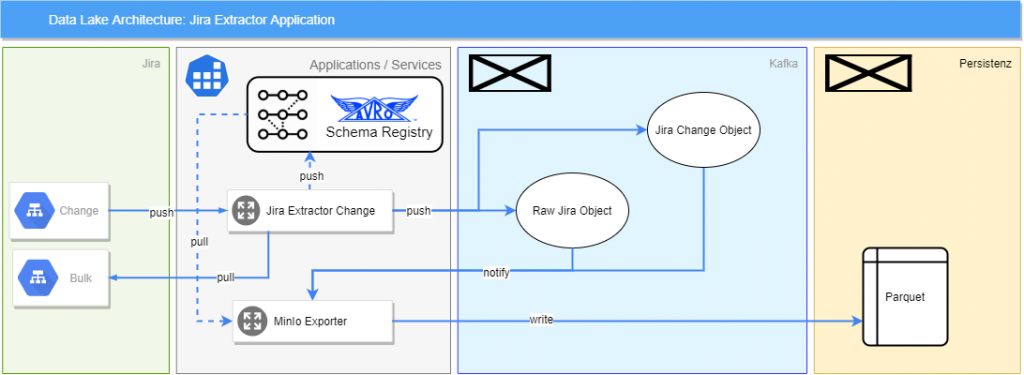
Jira Extraktion
Im konkreten Beispiel des Jira Servicedesk geschieht das durch ein Plugin, das neu angelegte und geänderte Service Requests erkennt und zur Ablage an den Data Lake sendet. Gleichzeitig überprüft der Service, der die Daten ablegt, ob sich die Struktur der Datensätze geändert hat. Dies kann bedeuten, dass ein neues Feld hinzugefügt wurde. Diese Änderungen werden in einer Avro Schema Registry gespeichert, sodass die Veränderung der Struktur von Data Scientists ebenso zur Lösungsentwicklung in Betracht gezogen werden kann. Änderungen oder Neuanlagen von Service Requests werden vom Jira Extractor erkannt und im JSON-Format in einen Topic geschrieben. Dort wird die Schemaänderung vom Exporter abgeholt und ebenfalls in den Data Lake geschrieben. Datensätze aus Jira werden im Parquet-Format in den Data Lake geschrieben, was ebenfalls eine Referenz auf die gültige Schema Version in der Registry erlaubt.
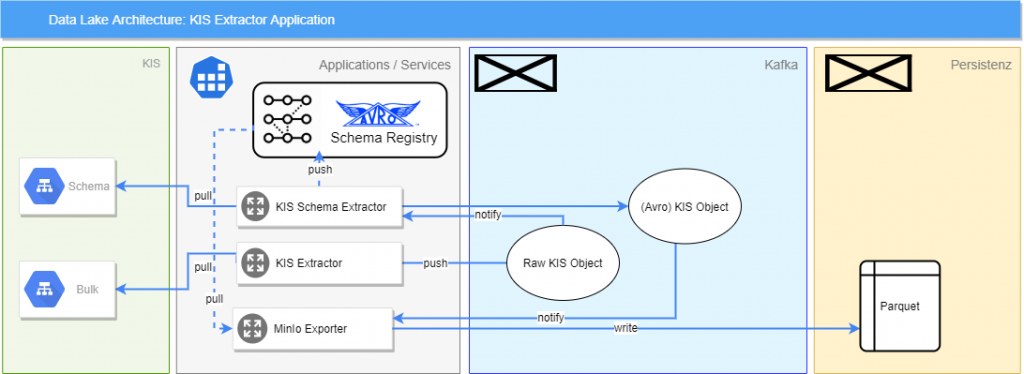
KIS Extraktor
Die Kundendaten liegen in diesem Fall in einer kundenseitigen Applikation auf FileMaker-Basis. FileMaker bietet eine REST-Schnittstelle, um die Daten zu extrahieren, zurückgegeben werden sie im JSON-Format. FileMaker bietet außerdem eine Schnittstelle zum Extrahieren der verwendeten Datenformate aller Felder, was die Extraktion des Schemas erleichtert. Die Daten werden jede Nacht abgerufen und als Batch verarbeitet. Dabei wird der KIS Extraktor zeitgesteuert alle Daten aus dem KIS anfordern und bekommt so Batches aus der Schnittstelle zurück. Diese werden nun in die einzelnen Objekte aufgeteilt und in einen Topic geschrieben. Hierdurch wird ebenfalls der Schema Extractor aufgefordert, das aktuelle Schema für den jeweiligen Datensatz zu prüfen. Der Schema Extractor nutzt eine Avro Schema Registry, um das Schema abzugleichen und gegebenenfalls fortzuschreiben. Alle einzelnen Objekte aus dem ursprünglichen Batch werden jetzt zu einem richtigen Objekt zusammengesetzt, welches im Avro-Format serialisiert wird. Das eigentliche Objekt wird dann im Parquet-Format in den Data Lake geschrieben.
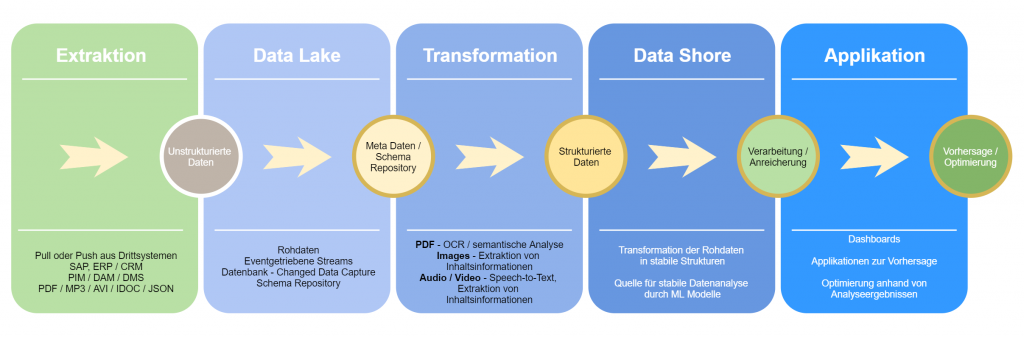
Grundlage für KI-Applikationen
MediFox hat nun die Möglichkeit, historische Rohdaten aus ihrem Data Lake zu nutzen, um eine Transformation in ein strukturiertes Format zu definieren und somit eine Grundlage für industrielle KI-Anwendungen geschaffen. Da keine Daten verloren gehen, können jederzeit auch Anwendungsfälle umgesetzt werden, an die beim Design des Data Lake noch niemand dachte. Neue Datenquellen lassen sich durch ein flexibles Design in Form einer servicebasierten Architektur hinzufügen. Ganz praktisch hat die Firma eine Anwendung geschaffen, die die Abwanderungswahrscheinlichkeit ermittelt, sobald genug Daten für eine Vorhersage vorliegen.