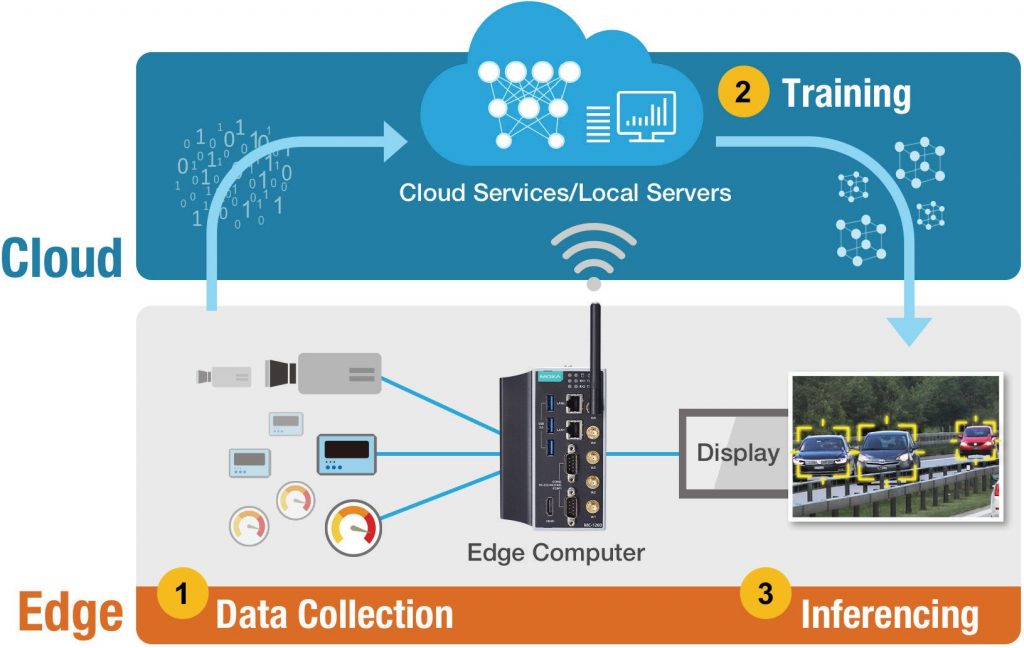
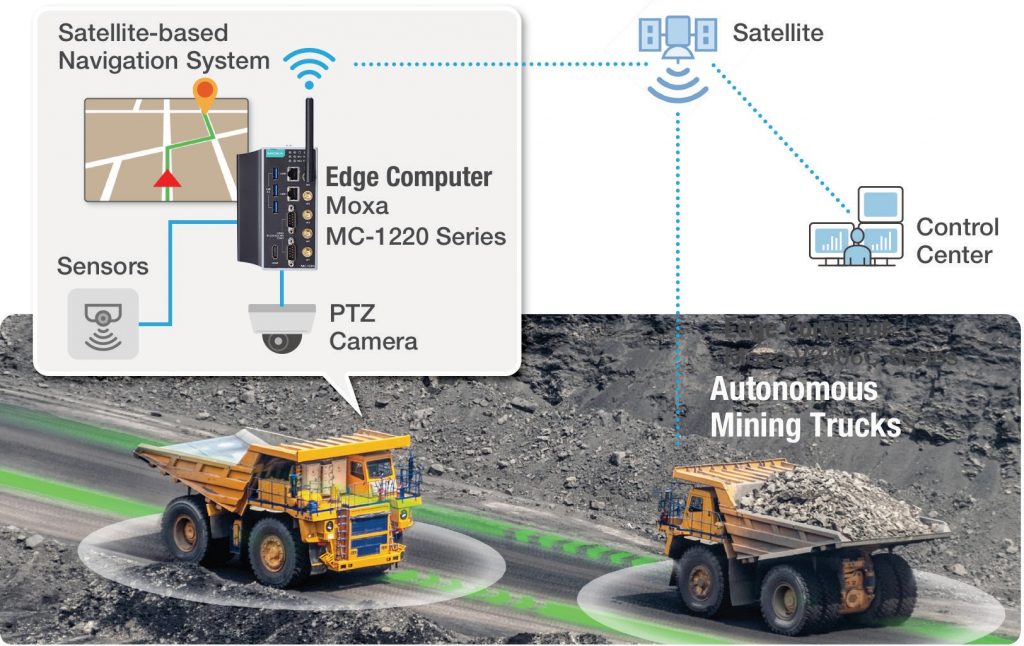
Die Sensoren und Geräte etwa einer großen Ölraffinerie produzieren rund ein Terabyte Rohdaten pro Tag. Eine sofortige Rücksendung all dieser Rohdaten zur Speicherung oder Verarbeitung an eine öffentliche Cloud oder einen privaten Server würde beträchtliche Ressourcen an Bandbreite, Verfügbarkeit und Stromverbrauch erfordern. Gerade in hochgradig verteilten Anlagen ist es gar unmöglich, solche Datenmengen an einen zentralen Server zu senden, bereits wegen der Latenzzeiten bei der Datenübertragung und -analyse. Um diese Latenzzeiten zu verkürzen, die Kosten für die Datenkommunikation und -speicherung zu senken und die Netzwerkverfügbarkeit zu erhöhen, werden bei IIoT-Anwendungen zunehmend KI- und Machine-Learning-Fähigkeiten auf die Edge-Ebene des Netzwerks verlagert, was eine größere Vorverarbeitungsleistung direkt vor Ort erlaubt. Die Fortschritte bei der Verarbeitungsleistung von Edge-Computern machen das möglich.
Der passende Edge-Computer
Um eine KI in die IIoT-Anwendungen zu integrieren, muss das Training der Modelle weiterhin in der Cloud stattfinden. Doch letztlich müssen die trainierten Interferenz-Modelle im Feld eingesetzt werden. Mit Edge-Computing kann das Interferenz über die KI im Wesentlichen vor Ort durchgeführt werden, anstatt Rohdaten zur Verarbeitung und Analyse an die Cloud zu senden. Dafür muss eine zuverlässige Hardwareplattform auf Edge-Niveau bereit stehen, bei deren Auswahl folgende Faktoren eine wichtige Rolle spielen: die Verarbeitungsanforderungen für verschiedene Phasen der KI-Implementierung, die Edge-Computing-Ebenen, Entwicklungstools und die Umgebungsbedingungen.
Phasen der Implementierung
Da jede der drei nachfolgenden Phasen des Aufbaus einer KI-Edge-Computing-Anwendung unterschiedliche Algorithmen zur Ausführung verschiedener Aufgaben verwendet, gelten in jeder Phase eigene Verarbeitungsanforderungen.
Datenerfassung – Ziel dieser Phase ist es, große Mengen an Informationen zu sammeln, um das KI-Modell zu trainieren. Unverarbeitete Rohdaten allein sind jedoch nicht hilfreich, da die Informationen Dubletten, Fehler und Ausreißer enthalten könnten. Die Vorverarbeitung der erfassten Daten in der Anfangsphase zur Identifizierung von Mustern, Ausreißern und fehlenden Informationen ermöglicht außerdem das Korrigieren von Fehlern und systematischen Verzerrungen. Je nach Komplexität der erfassten Daten basieren die bei der Datenerfassung typischerweise verwendeten Computerplattformen meist auf Prozessoren der Serien Arm Cortex oder Intel Atom/Core. Im Allgemeinen sind die E/A- und CPU-Spezifikationen (und nicht die der GPU) wichtiger für die Durchführung von Datenerfassungsaufgaben.
Training – KI-Modelle müssen auf modernen neuronalen Netzen und ressourcenintensiven Machine-Learning- oder Deep-Learning-Algorithmen trainiert werden, die leistungsfähigere Verarbeitungsfunktionen etwa von GPUs erfordern. Deren Fähigkeiten bei der Parallelverarbeitung helfen, große Mengen von erfassten und vorverarbeiteten Trainingsdaten zu analysieren. Das Training eines KI-Modells beinhaltet die Auswahl eines Machine-Learning-Modells und dessen Training anhand der erfassten und vorverarbeiteten Daten. Während dieses Prozesses müssen auch die Parameter bewertet und entsprechend angepasst werden. Es stehen zahlreiche Trainingsmodelle und Tools zur Auswahl, darunter auch Deep-Learning-Entwicklungs-Frameworks nach Industriestandards wie PyTorch, TensorFlow und Caffe. Das Training wird üblicherweise auf dafür vorgesehenen KI-Trainingsmaschinen oder Cloud-Computing-Diensten wie den AWS Deep Learning AMIs, Amazon SageMaker Autopilot, Google Cloud AI oder Azure Machine Learning durchgeführt.
Interferenz – In der letzten Phase wird das trainierte KI-Modell auf dem Edge-Computer implementiert, damit es Schlussfolgerungen und Vorhersagen auf der Grundlage neu erfasster und vorverarbeiteter Daten treffen kann. Da die Inferencing-Phase im Allgemeinen weniger Datenverarbeitungsressourcen verbraucht als das Training, kann eine CPU oder ein leichter Beschleuniger für die betreffende AIoT-Anwendung reichen. Dennoch wird ein Konvertierungstool benötigt, um das trainierte Modell so umzuwandeln, dass es auf speziellen Edge-Prozessoren/Beschleunigern ausgeführt werden kann, etwa Intel OpenVino oder Nvidia Cuda. Interferenz umfasst auch mehrere verschiedene Edge-Computing-Ebenen und -Anforderungen, auf die im folgenden Abschnitt eingegangen wird.
Edge-Computing-Ebenen
Obwohl die KI immer noch hauptsächlich in der Cloud oder auf lokalen Servern traininert wird, finden die Datenerfassung und das Inferencing notwendigerweise am Netzwerk-Rand statt. Da das Inferencing die Phase ist, in der das trainierte KI-Modell die meiste Arbeit leistet, um die Anwendungsziele zu erreichen – also Entscheidungen zu treffen oder Aktionen auf der Grundlage neu erfasster Felddaten durchzuführen – muss zur Auswahl des passenden Prozessors festgelegt werden, welche der folgenden Edge-Computing-Ebenen benötigt werden: Künstliche Intelligenz (KI) verspricht die Revolution der Fertigung, doch in der Praxis scheitern viele Projekte an einer unzureichenden Datenbasis. Warum Sie erst Ordnung schaffen müssen, bevor Sie Künstliche Intelligenz erfolgreich nutzen können. ‣ weiterlesen
Ohne Datenordnung keine Effizienz: Wie Sie Ihre Produktion KI-ready machen
Untere Edge-Computing-Ebene – Das Übertragen von Daten zwischen Edge und Cloud ist teuer, zeitraubend und führt zu Latenzzeiten. Beim Low-Edge-Computing wird nur eine kleine Menge an Nutzdaten an die Cloud gesendet, was die Verzögerungszeit, die Bandbreite, die Datenübertragungsgebühren, den Energieverbrauch und die Hardwarekosten reduziert. Eine ARM-basierte Plattform ohne Beschleuniger kann auf IIoT-Geräten verwendet werden, um Daten zu erfassen und zu analysieren, um so schnelle Schlussfolgerungen zu ziehen oder Entscheidungen zu treffen.
Mittlere Edge-Computing-Ebene – Diese Inferencing-Ebene kann verschiedene IP-Kamerastreams für die computergestützte Bildverarbeitung oder Videoanalyse mit ausreichenden Verarbeitungsbildraten abwickeln. Das Medium-Edge-Computing umfasst ein breites Spektrum an Datenkomplexität auf der Grundlage des KI-Modells und der Leistungsanforderungen des Anwendungsfalls wie der Gesichtserkennung für ein Büro-Eingangssystem, verglichen mit einem großen öffentlichen Überwachungsnetz. Bei den meisten industriellen Edge-Computing-Anwendungen müssen außerdem Aspekte wie ein begrenztes Energiebudget oder ein lüfterloses Design zur Wärmeableitung berücksichtigt werden. So können auf dieser Ebene möglicherweise eine Hochleistungs-CPU, eine GPU der Einstiegsklasse oder eine VPU verwendet werden. Beispielsweise stellen die CPUs der Serie Intel Core i7 eine effiziente Computer-Vision-Lösung mit dem OpenVino-Toolkit und softwarebasierten KI-/ML-Beschleunigern dar, die das Inferencing auf Edge-Ebene durchführen können.
Obere Edge-Computing-Ebene – Beim High-Edge-Computing werden größere Datenmengen für KI-Expertensysteme verarbeitet, die mit einer komplexeren Mustererkennung arbeiten, beispielsweise für die Verhaltensanalyse bei der automatischen Videoüberwachung in öffentlichen Sicherheitssystemen, mit der Sicherheitsvorfälle oder potenziell bedrohliche Ereignisse erkannt werden können. Beim Inferencing auf der oberen Edge-Computing-Ebene werden meist Beschleuniger verwendet, darunter High-End-GPUs, VPUs, TPUs oder FPGAs, die mehr Leistung (200 Watt oder höher) verbrauchen und Abwärme erzeugen. Da der erforderliche Energieverbrauch und die erzeugte Wärme die Grenzwerte am entfernten Rand des Netzwerks überschreiten können, werden High-Edge-Computersysteme häufig an randnahen Standorten eingesetzt.
Entwicklungstools
Für verschiedene Hardware-Plattformen stehen mehrere Tools zur Verfügung, die den Prozess der Anwendungsentwicklung beschleunigen oder die Gesamtleistung für KI-Algorithmen und maschinelles Lernen verbessern.
Frameworks für Deep Learning
In Betracht kommt die Verwendung eines Deep-Learning-Frameworks, das heißt einer Oberfläche, einer Bibliothek oder eines Tools, mit dem sich Deep-Learning-Modelle einfacher und schneller erstellen lassen, ohne dass man sich mit den Details der ihnen zugrunde liegenden Algorithmen auseinandersetzen muss. Deep-Learning-Frameworks bieten eine klar umrissene Möglichkeit zur Definition von Modellen unter Verwendung einer Sammlung von vorgefertigten und optimierten Komponenten. Die drei beliebtesten sind:
PyTorch – PyTorch wurde in erster Linie von Facebook entwickelt und ist eine Open-Source-Bibliothek für maschinelles Lernen, die auf der Torch-Bibliothek basiert. Die freie und quelloffene Software wurde unter der modifizierten BSD-Lizenz veröffentlicht und wird für Anwendungen wie Computer-Vision und die Verarbeitung von natürlicher Sprache eingesetzt.
TensorFlow – Ermöglicht schnelles Prototyping, Forschung und Produktion mit den benutzerfreundlichen Keras-basierten APIs von TensorFlow, die zum Definieren und Trainieren neuronaler Netzwerke verwendet werden.
Caffe – Caffe zeichnet sich durch seine Architektur aus, mit der sich Modelle und Optimierungen ohne harte Codierung definieren und konfigurieren lassen. In Caffe kann ein einzelnes Flag gesetzt werden, um das Modell auf einer GPU-Maschine zu trainieren und es dann auf Warenclustern oder mobilen Geräten zu implementieren.
Beschleuniger-Toolkits
KI-Beschleuniger-Toolkits werden von Hardware-Herstellern angeboten und sind speziell für die Beschleunigung von KI-Anwendungen wie maschinellem Lernen und Computer-Vision auf ihren Plattformen konzipiert.
Intel OpenVino – Das Toolkit Open Visual Inference and Neural Network Optimization von Intel wurde dafür konzipiert, Entwicklern beim Erstellen robuster Anwendungen für Computer-Vision auf Intel-Plattformen zu helfen. OpenVINO ermöglicht außerdem ein schnelleres Inferencing für Deep-Learning-Modelle.
Nvidia Cuda – Das Cuda-Toolkit ermöglicht leistungsstarkes Parallel-Computing für GPU-beschleunigte Anwendungen auf eingebetteten Systemen, Rechenzentren, Cloud-Plattformen und Supercomputern, die auf der Compute Unified Device Architecture von Nvidia basieren.
Auf Umgebung abgestimmt
Industrielle Anwendungen, die im Freien oder unter schwierigen Umgebungsbedingungen zum Einsatz kommen, sollten einen weiten Betriebstemperaturbereich aufweisen und über geeignete Mechanismen zur Wärmeableitung verfügen. Bestimmte Anwendungen erfordern zudem branchenspezifische Zertifizierungen oder Zulassungen wie ein lüfterloses Design, einen explosionsgeschützten Aufbau und Vibrationsfestigkeit. Da außerdem viele reale Anwendungen in Schränken mit begrenztem Platzangebot eingesetzt werden und somit Größenbeschränkungen unterliegen, werden Edge-Computer mit kleinem Formfaktor oft bevorzugt. Überdies können hochgradig dezentral organisierte Industrieanwendungen an entlegenen Standorten auch eine Kommunikation über eine zuverlässige Mobilfunk- oder WLAN-Verbindung erfordern. Beispielsweise macht ein industrietauglicher Edge-Computer mit integrierter LTE-Mobilfunkkonnektivität ein zusätzliches Mobilfunk-Gateway überflüssig und spart Platz im Schaltschrank und Kosten für die Bereitstellung. Eine weitere Überlegung ist, dass eine redundante Mobilfunkverbindung mit Dual-SIM-Unterstützung erforderlich sein kann, damit Daten auch dann übertragen werden, wenn das Signal eines Mobilfunknetzes schwach ist oder ausfällt.
Zusammenfassung
Bei der Auswahl der Rechnerplattform für eine AIoT-Anwendung sollten die spezifischen Verarbeitungsanforderungen in den drei Phasen der Implementierung berücksichtigt werden: Datenerfassung, Training und Inferencing. Für die Inferencing-Phase muss auch das Niveau der Edge-Computing-Ebene (niedrig, mittel oder hoch) festgelegt werden, so dass der am besten geeignete Prozessortyp ausgewählt werden kann. Durch sorgfältige Evaluierung der Anforderungen der geplanten AIoT-Anwendung in jeder Phase kann der am besten geeignete Edge-Computer ausgewählt werden.