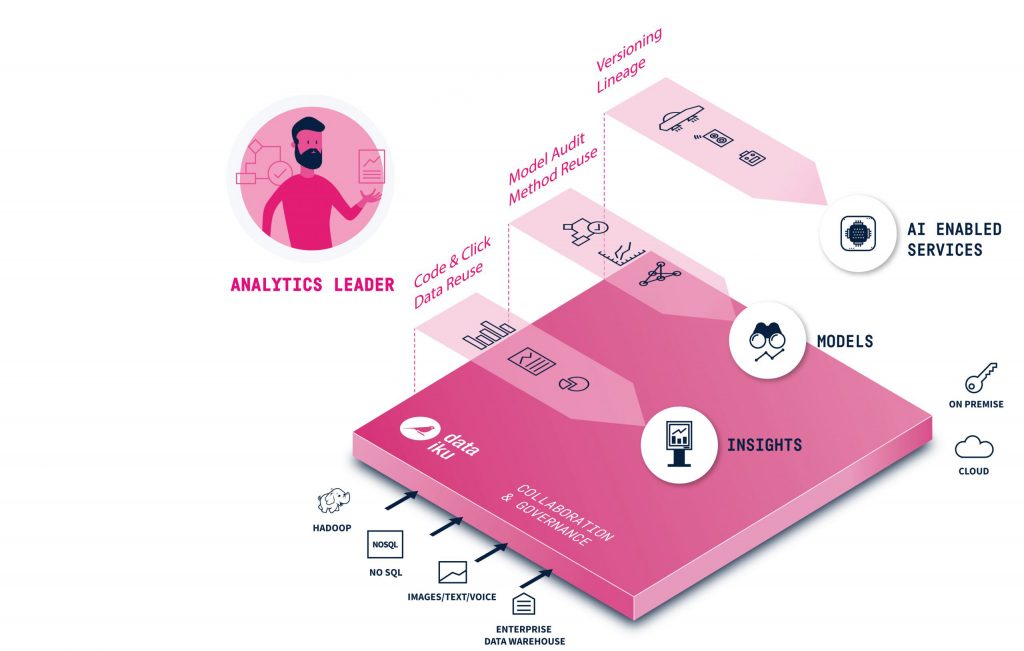
Data Science in der Produktion bietet viele Möglichkeiten, etwa die vorausschauende Wartung von Fertigungsanlagen. Aber auch Logistik, Personaleinsatzplanung, Qualitätskontrolle und Produktionssteuerung lassen sich durch die Analyse bestehender Daten optimieren. Doch erfüllen einzelne Data-Science-Projekte oft nicht die Erwartungen, wenn die grundlegende Voraussetzungen zum strategischen Umgang mit Daten fehlen. Um schnell sichtbare Erfolge zu erzielen, sollten die Daten an einer zentralen Stelle verfügbar sein. Die Experten aus den Fachabteilungen müssen als Teil des Projektteams in definierten Rollen mit Data Scientists zusammenarbeiten. Gleichzeitig sollte sichergestellt werden, dass die Daten vertrauenswürdig sind. Eine unternehmensweite Data Science-Plattform kann diese Voraussetzungen schaffen.
Verschiedene Komponenten
Um alle Funktionen und Prozesse rund um die Daten zentral steuern und überwachen zu können, vereint eine Data-Science-Plattform unterschiedliche Softwarekomponenten – beispielsweise zur Bereinigung und Aufbereitung der Daten – die alle über eine zentrale Oberfläche bedient werden. Ebenso können Machine-Learning-Anwendungen direkt erstellt und angewendet werden. Auch Auswertungs- und Visualisierungsfunktionen sind Teil der Software. Schließlich wird über die Plattform auch die Verteilung der Data-Science-Lösungen vorgenommen, die dann auch darüber überwacht werden.
Vorteile von Open Source
Interessant können jene Plattformen sein, die neben integrierten Software-Tools Schnittstellen zu Open-Source-Technologien bieten. Diese tragen zur Verbreitung von Data Science und Machine Learning bei. Zudem werden Open-Source-Lösungen oft an Universitäten genutzt. Neu eingestellte Mitarbeiter können sich schneller einarbeiten, wenn sie bereits Erfahrungen mit den Tools gesammelt haben.
Basis schaffen für Kooperation
Im betrieblichen Alltag geht oft viel Zeit bei der Suche nach Informationen oder durch unklare Prozesse verloren, wodurch etwa Aufgaben in Fachabteilungen doppelt erledigt werden. Isolierte Data-Science-Projekte bergen dieses Risiko ebenfalls. Daher sollte Zusammenarbeit orchestriert, Verantwortlichkeit definiert und Regeln zur Data Governance eingerichtet werden. Date-Science-Plattformen sollten Werkzeuge für diese Aufgaben mitbringen.
System im Wandel
Ein Unterschied zwischen der meisten Softwares und Machine-Learning-Modellen ist ihre Wartung. Die meiste Software wird einmal entwickelt und hin und wieder aktualisiert. Machine Learning-Modelle hingegen werden entwickelt, produktiv gestellt und dann kontinuierlich überwacht sowie verbessert. Auch wenn die Leistung zunächst gut erscheint, kann sie sich mit neuen Daten schnell ändern. Wird dieser Aspekt vernachlässigt, kann das große Auswirkungen auf die Anstrengungen haben. Denkt man nun einen Schritt weiter in Richtung Automated Machine Learning oder Self Service Analytics, geht es auch darum, einmal geleistete Arbeit zu sichern. Dazu bieten viele Data-Science-Plattformen mit Option, Prozesse zu dokumentieren und Algorithmen zu speichern. Einmal aufbereitete Daten sind so leichter für weitere Projekte zu finden.
Hilfe beim Modell-Rollout
Ob ein entwickeltes Datenmodell den gewünschten Effekt erzielt, zeigt sich erst im operativen Betrieb. Über Programmierschnittstellen (API) verteilen Data-Science-Plattformen die Modelle ohne weitere Programmierarbeit. Ein solcher Schritt kostet Zeit und stellt eine Hürde dar. Über ein in der Plattform integriertes Werkzeug kann dieser Bruch verhindert werden.
Verschiedene Ausprägungen
All diese Anforderungen und grundlegenden Funktionen gelten für annähernd alle Data-Science-Plattformen. Darüber hinaus unterscheiden sich die Lösungen hinsichtlich Ihrer Funktionalität. Dataiku verfolgt als Anbieter einer solchen Plattform beispielsweise das Ziel, Data Science und Machine Learning zu demokratisieren. Sie soll eine strukturierte Zusammenarbeit zwischen Datenexperten und Anwendern ermöglichen und liefert eine Bibliothek mit Best Practices.