Das große KI-Sprachmodell des Forschungsprojekts OpenGPT-X steht ab sofort auf Hugging Face zum Download bereit: ‚Teuken-7B‘ wurde von Grund auf mit den 24 Amtssprachen der EU trainiert und umfasst sieben Milliarden Parameter. Akteure aus Forschung und Unternehmen können das kommerziell einsetzbare Open-Source-Modell fu?r ihre eigenen Anwendungen der Ku?nstlichen Intelligenz (KI) nutzen. Damit haben die Partner des vom Bundesministerium fu?r Wirtschaft und Klimaschutz (BMWK) geförderten Konsortialprojekts OpenGPT-X unter der Leitung der Fraunhofer-Institute fu?r Intelligente Analyse- und Informationssysteme IAIS und fu?r Integrierte Schaltungen IIS ein großes KI-Sprachmodell als frei verwendbares Open-Source-Modell mit europäischer Perspektive auf den Weg gebracht.
„Im Projekt OpenGPT-X haben wir in den vergangenen zwei Jahren mit starken Partnern aus Forschung und Wirtschaft die grundlegende Technologie fu?r große KI-Fundamentalmodelle erforscht und entsprechende Modelle trainiert. Wir freuen uns, dass wir jetzt unser Modell ‚Teuken-7B‘ weltweit frei zur Verfu?gung stellen und damit eine aus der öffentlichen Forschung stammende Alternative fu?r Wissenschaft und Unternehmen bieten können“, sagt Prof. Dr. Stefan Wrobel, Institutsleiter am Fraunhofer IAIS. „Unser Modell hat seine Leistungsfähigkeit u?ber eine große Bandbreite an Sprachen gezeigt, und wir hoffen, dass möglichst viele das Modell fu?r eigene Arbeiten und Anwendungen adaptieren oder weiterentwickeln werden. So wollen wir sowohl innerhalb der wissenschaftlichen Community als auch gemeinsam mit Unternehmen unterschiedlicher Branchen einen Beitrag leisten, um den steigenden Bedarf nach transparenten und individuell anpassbaren Lösungen der generativen Ku?nstlichen Intelligenz zu adressieren.“ Künstliche Intelligenz (KI) verspricht die Revolution der Fertigung, doch in der Praxis scheitern viele Projekte an einer unzureichenden Datenbasis. Warum Sie erst Ordnung schaffen müssen, bevor Sie Künstliche Intelligenz erfolgreich nutzen können. ‣ weiterlesen
Ohne Datenordnung keine Effizienz: Wie Sie Ihre Produktion KI-ready machen
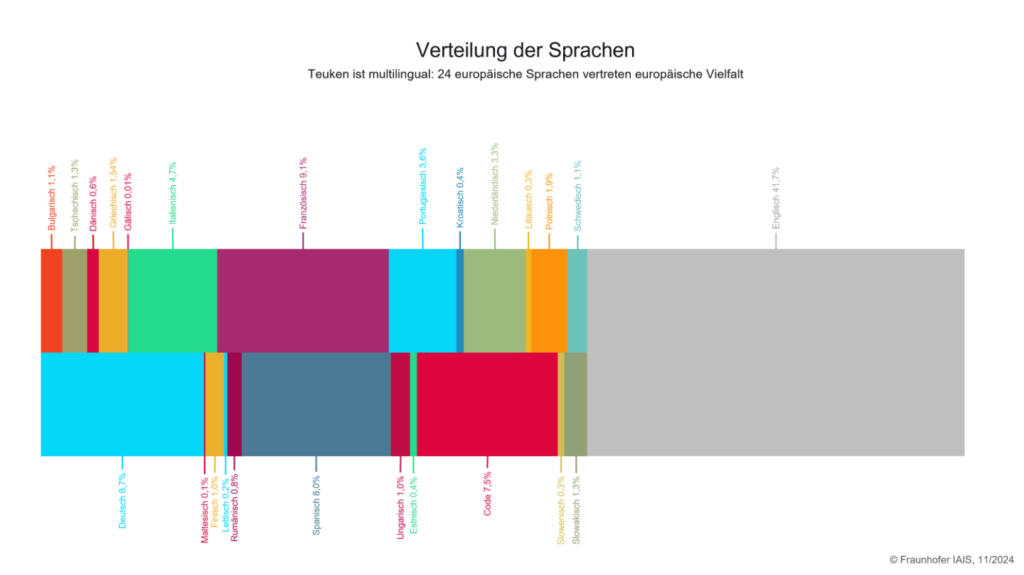
Teuken-7B ist aktuell eines der wenigen KI-Sprachmodelle, die von Grund auf multilingual entwickelt wurden. Es enthält ca. 50 Prozent nicht-englische Pretraining-Daten und wurde in allen 24 europäischen Amtssprachen trainiert. Es erweist sich u?ber mehrere Sprachen hinweg in seiner Leistung als stabil und zuverlässig. Dies bietet insbesondere internationalen Unternehmen mit mehrsprachigen Kommunikationsbedarfen sowie Produkt- und Serviceangeboten einen Mehrwert. Die Bereitstellung als Open-Source-Modell erlaubt es Unternehmen und Organisationen, eigene angepasste Modelle in realen Anwendungen zu betreiben. Sensible Daten können im Unternehmen verbleiben.
Das Verbundprojekt OpenGPT-X wurde im Rahmen des BMWK-Förderprogramms ‚Innovative und praxisnahe Anwendungen und Datenräume im digitalen Ökosystem Gaia-X‘ gefördert. Somit ist Teuken-7B auch u?ber die Gaia-X Infrastruktur zugänglich. Akteure im Gaia-X-Ökosystem können so innovative Sprachanwendungen entwickeln und in konkrete Anwendungsszenarien in ihren jeweiligen Domänen u?berfu?hren. Im Gegensatz zu bestehenden Cloud-Lösungen handelt es sich bei Gaia-X um ein föderiertes System, u?ber das sich unterschiedliche Dienstanbieter und Dateneigentu?mer miteinander verbinden können. Die Daten verbleiben stets beim Eigentu?mer und werden ausschließlich nach festgelegten Bedingungen geteilt.