Immer mehr Anwendungen direkt am Netzwerkrand sind auf leistungsfähige KI-Modelle und schelle Reaktionszeiten angewiesen – von Smart Homes über Angebote im Bereich Smart Security bis zu autonomen Fahrzeugen. Kommt es auf Millisekunden an, fällt die Wahl meistens auf eine Edge-AI-Architektur, die Rechenressourcen und Speicherkapazitäten direkt vor Ort bereitstellt. Diese Strategie ist allerdings kein Selbstläufer, Unternehmen sollten sich daher im Vorfeld der größten Herausforderungen von Edge AI bewusst werden – insbesondere die Wahl einer passenden Datenbank erhält dabei eine zentrale Bedeutung.
1. Stolperstein: Die lokale Datenverwaltung. Edge-Geräte verfügen in der Regel über eine limitierte Rechenleistung und stark begrenzten Speicherplatz, die den Einsatz einer leichtgewichtigen Datenbank notwendig machen. In der Praxis haben sich dabei NoSQL-Datenbanken bewährt, die sowohl Server- als auch Embedded-Versionen aus einer Hand anbieten und über ein flexibles Datenmodell verfügen.
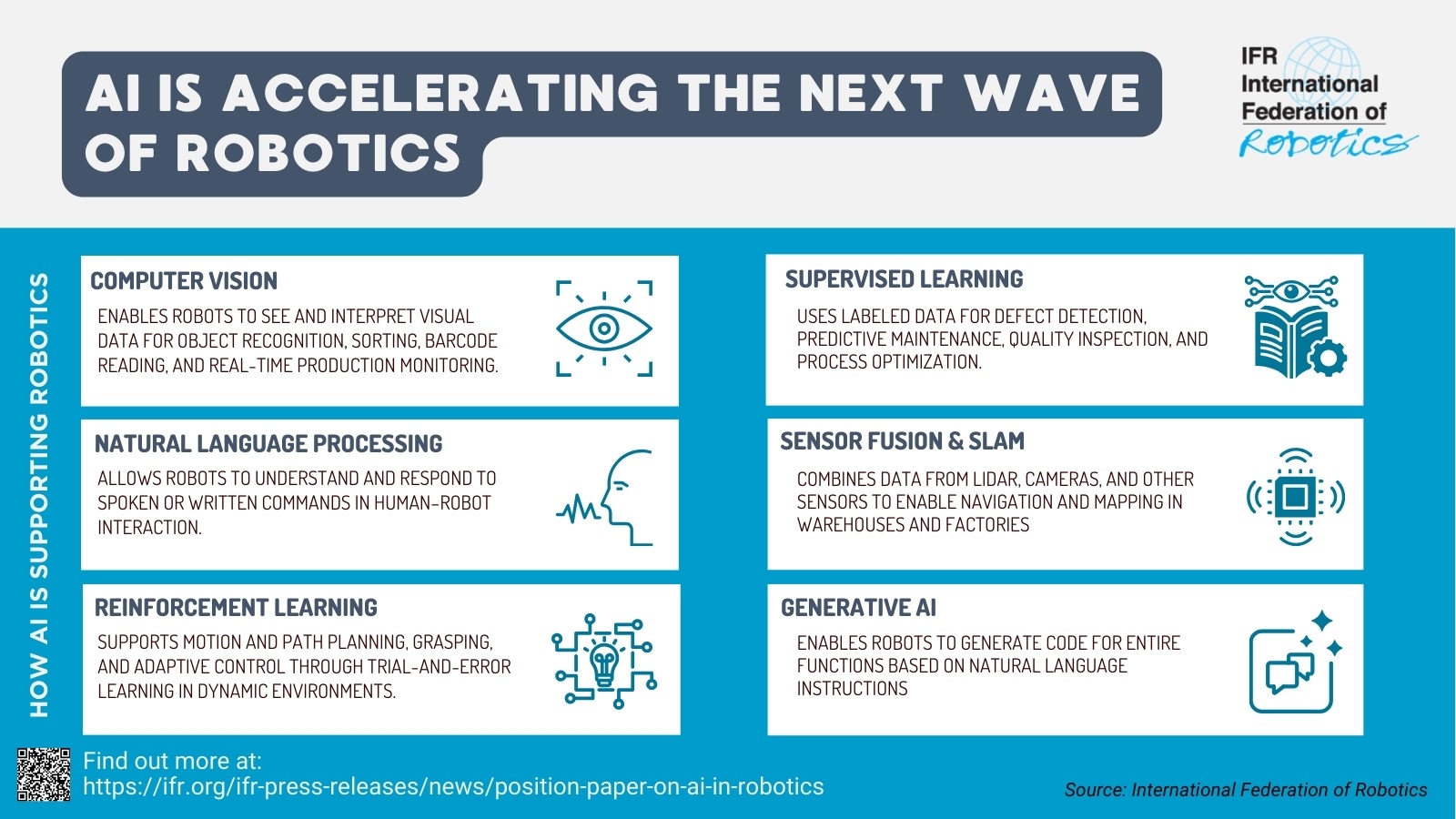
2. Stolperstein: Die KI-Modelle. Die meisten LLMs (Large Language Models) sind zu groß und benötigen zu viele Ressourcen, für das Einsetzen am Edge. Es gibt jedoch eine wachsende Zahl von Modellen, die für die Ausführung auf mobilen und IoT-Geräten optimiert sind. Der Kompromiss besteht in der Regel darin, dass kleinere Modelle meist weniger genau sind als ihre Cloud-basierten Pendants. Der große Nutzen von Echtzeitperformance und Sicherheit, die eine lokale Verarbeitung erreicht, ist diesen Kompromiss allerdings in jedem Falle wert. Künstliche Intelligenz (KI) verspricht die Revolution der Fertigung, doch in der Praxis scheitern viele Projekte an einer unzureichenden Datenbasis. Warum Sie erst Ordnung schaffen müssen, bevor Sie Künstliche Intelligenz erfolgreich nutzen können. ‣ weiterlesen
Ohne Datenordnung keine Effizienz: Wie Sie Ihre Produktion KI-ready machen
3. Stolperstein: Konnektivität und Bandbreitenbeschränkungen. In vielen Edge-Anwendungen, insbesondere in abgelegenen oder mobilen Umgebungen, kann die Netzwerkverbindung instabil oder die Bandbreite begrenzt sein. Edge-AI-Lösungen müssen daher in der Lage sein, ohne permanente Internetverbindung zu funktionieren, gleichzeitig die über das Netzwerk übertragene Datenmenge zu minimieren und über Offline-First-Funktionen verfügen.
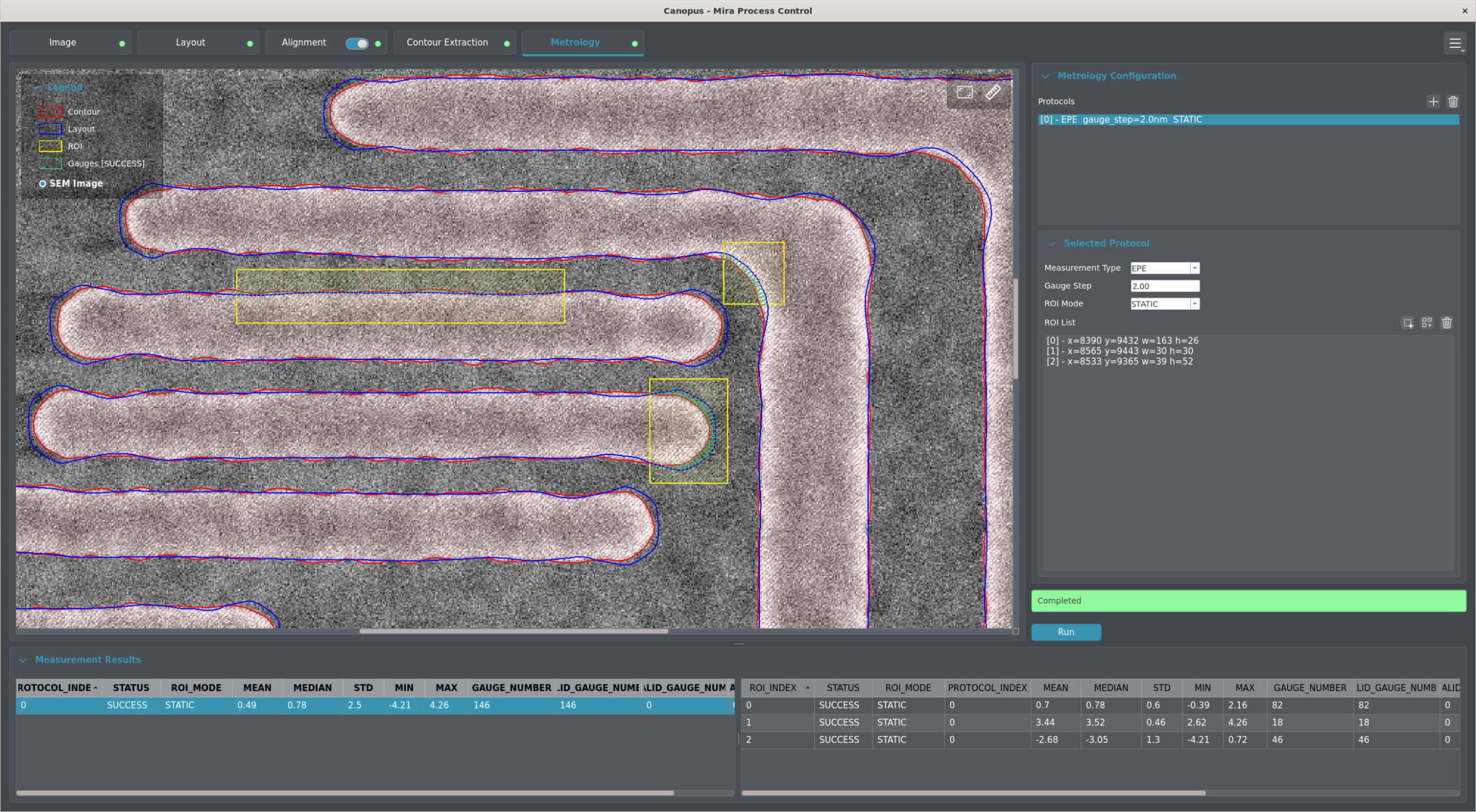
4. Stolperstein: Die Synchronisation. Die Synchronisierung von Daten ist in einer verteilten Anwendung erforderlich, um die Integrität zu wahren. Das gesamte App-Ökosystem muss also in der Lage sein, auf Änderungen zu reagieren. Die Replikation aller Inhalte kann allerdings zu Schreibkonflikten führen. Die eingesetzte Datenbank sollte daher über die Fähigkeiten verfügen, nur ausgewählte Daten unabhängiger Datenbank-Cluster zu replizieren sowie Lese- und Schreibkonflikte selbstständig zu lösen.
„Edge AI ist ein Architekturansatz mit riesigem Potenzial, der Anwendungen schneller, sicherer und intelligenter machen kann – wenn Unternehmen ihn richtig umsetzen“, sagt Gregor Bauer, Manager Solutions Engineering CEUR bei Couchbase. „Ganz oben steht dabei die Wahl der richtigen Datenbank. Mit ihr steht und fällt die Leistungsfähigkeit und Funktionalität der KI am Netzwerkrand.“