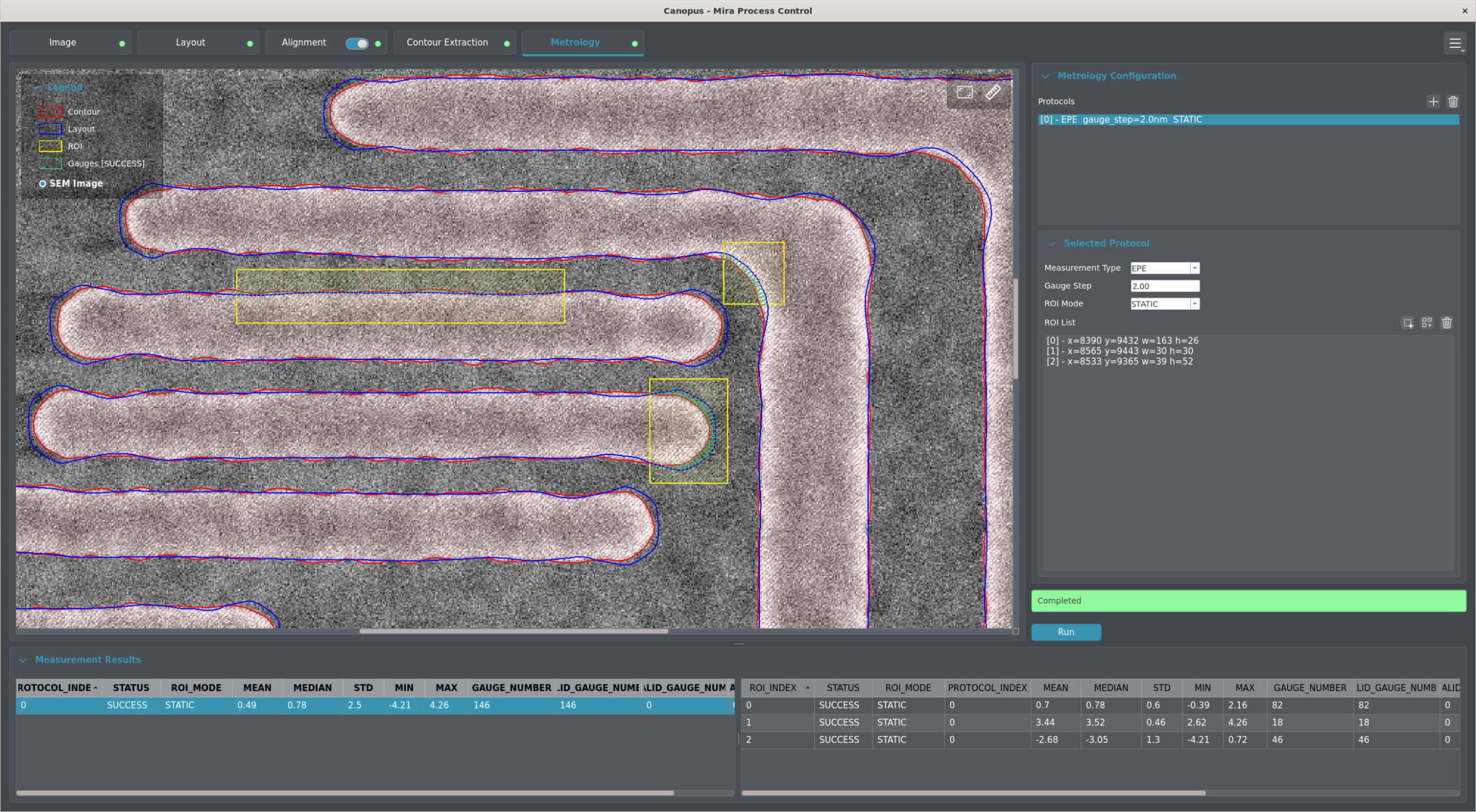
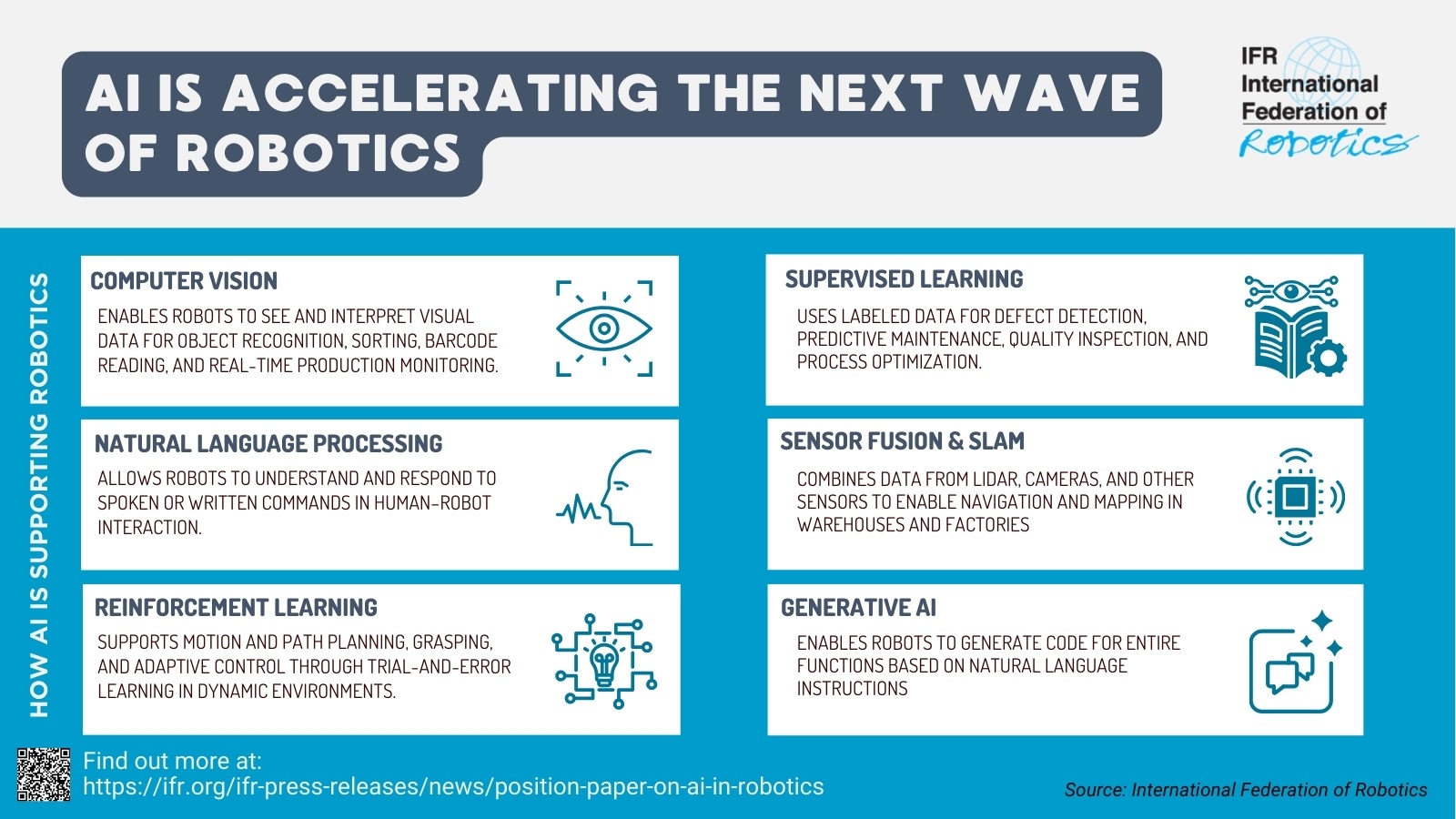
One of the key trends in the field of vision is the rise of visual language models. Visual language models combine computer vision (CV) and natural language processing (NLP) by processing both image content and text data simultaneously. This technology enables tasks such as automatic image descriptions, visual question answering, and understanding complex documents. In 2026, VLMs will drive the growth of AI because they interpret multimodal data efficiently and context-sensitively. VLMs are used in particular on edge devices, i.e., locally operated, resource-constrained end devices – for example, in visual quality control in production, where VLMs analyze and document products directly on site without the need for a cloud server. This becomes even more powerful when the models are expanded to include an action layer, enabling robotic systems to perform the tasks required in the respective setting. In this case, we refer to a vision-language-action model (VLA).