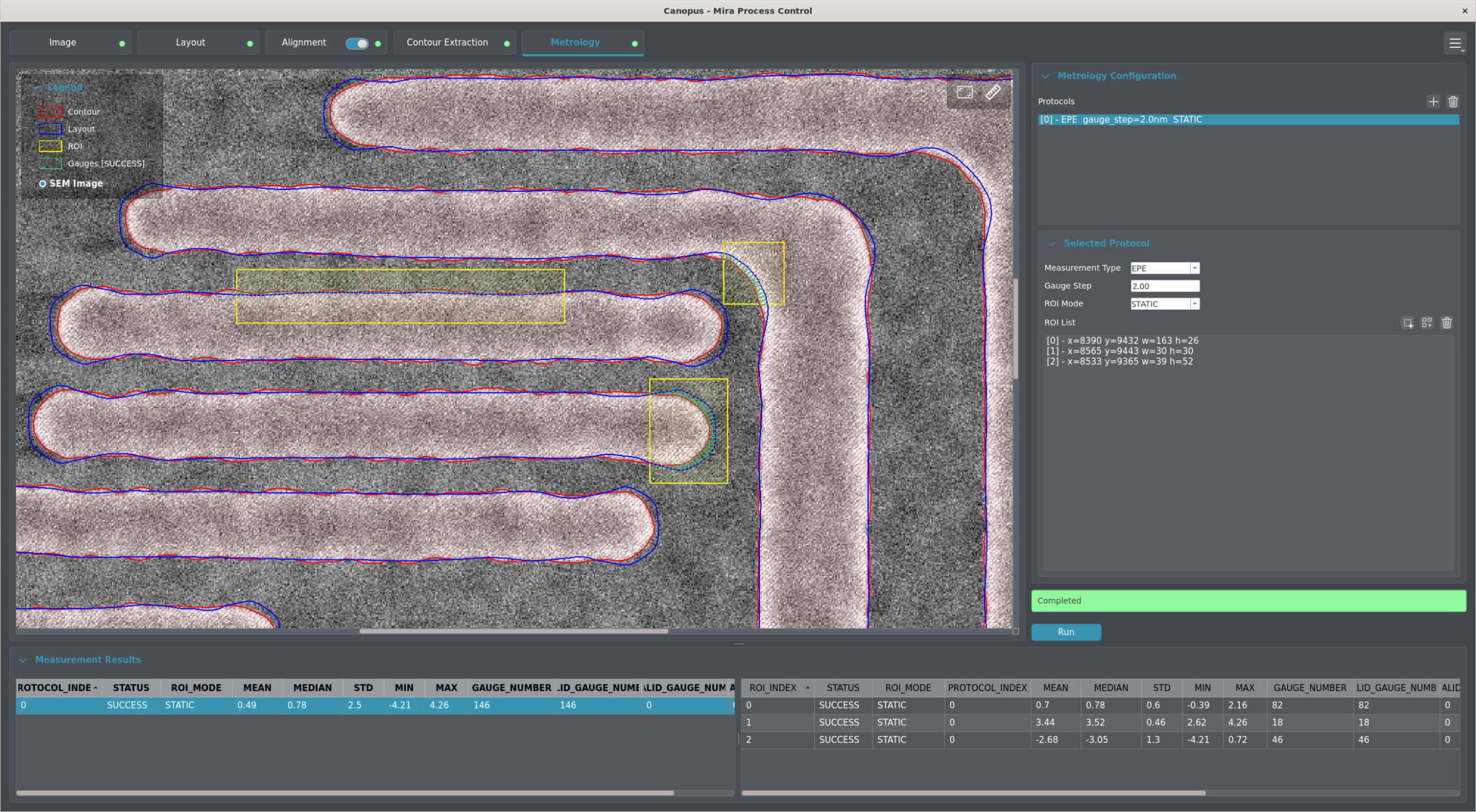
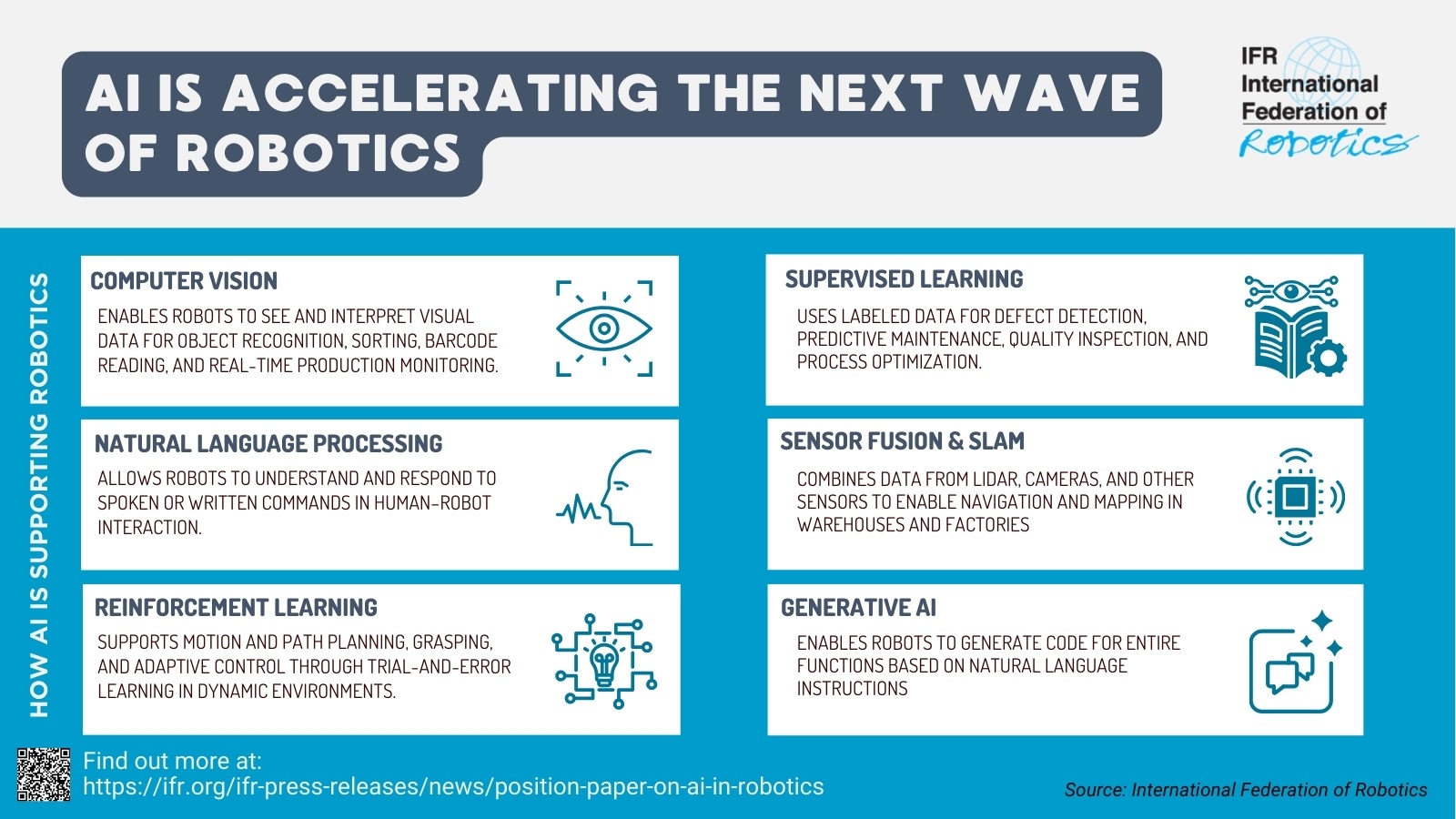
Um in modernen Produktionsstätten eine sichere und reibungslose Zusammenarbeit zu gewährleisten, müssen Cobots ihre Umgebung visuell erfassen, gesprochene Anweisungen verstehen sowie die Absichten und Handlungen menschlicher Kollegen antizipieren und interpretieren können. Ein wesentlicher Faktor hierfür ist der Einsatz zusätzlicher Sensorik, insbesondere Gaze- und Pose-Tracking. Diese Daten werden zusammen mit Bild- und Sprachdaten in Vision-Language-Action-Modelle integriert, um ein multimodales Situationsverständnis zu erzeugen. Die Modelle können nicht nur auf sprachliche Anweisungen und visuelle Hinweise reagieren, sondern auch den nächsten Arbeitsschritt antizipieren, indem sie die Blickrichtung und Körperhaltung des Menschen interpretieren. Dadurch wird der Roboter zu einem proaktiven und aufmerksamen Teamplayer.